理解Tomcat主要的架构设计、核心组件设计、功能实现以及性能优化方案,细数我目前对Tomcat掌握的知识。
原先打算按照深入浅出系列的结构来讲解本文,后来想想这种文章别人早就已经写过了,那倒不如我们就抱着一个简单的想法「从Tomcat中我们学到什么?」来试试把本文填满。
Servlet之于Java,相当于wsgi之于Python。我之前看到微博有人发牢骚「不懂Python的wsgi为什么要把web开发搞的这么复杂?!」,其实这个问题很好解答,如果我们只做简单的项目,我们就不需要Tomcat,甚至不需要Spring、SpringMVC,简单到一定程度连Http协议都不需要了。
简单的需求我们直接用原生@WebServlet的方式处理接口逻辑,足矣。
但是我们的Web后端可以这么简单吗?
肯定不能!
1.架构组件抽象
常见的中间件、技术组件单独拿出来做的一个原因是:分离了服务中变化与不变的内容,而技术组件只负责不变的内容。这就是解耦!
比如本文要聊的Tomcat作为HTTP服务器实现了网络协议的连接、转换、传输功能,同时作为Servlet容器实现了接入业务接口的功能。
针对Tomcat的核心组件画了个图:
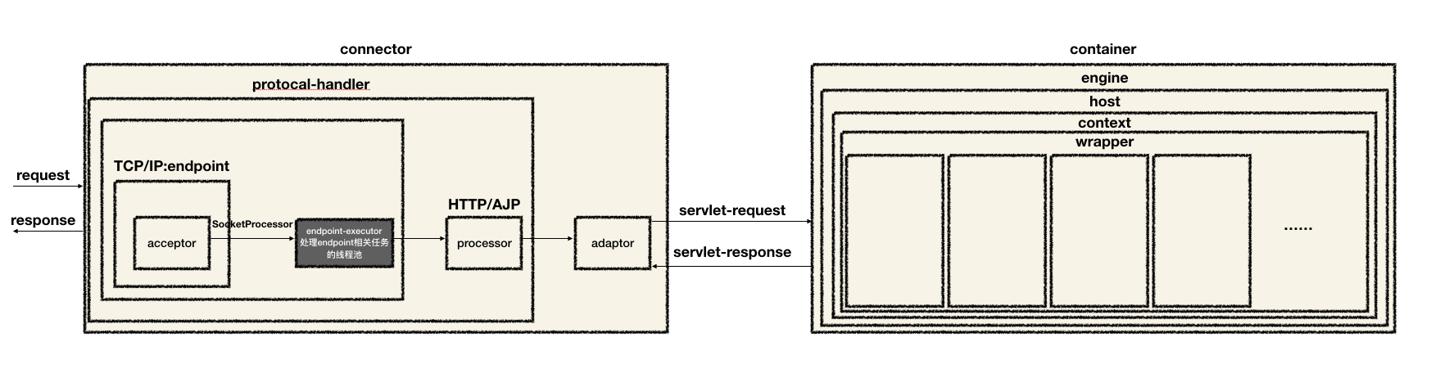
结合一下我们平时的应用系统设计,特别是需求多、系统庞杂的情况下,针对组件做一定的解耦、抽象是必须的,这一点完全可以跟着Tomcat的样子学习:
- 职责不同的组件抽出来
- 层级关系、节点关系可以通过组件表达出来
- 通过合适的设计模式设计组件,比如
Tomcat中大量使用了模板方法模式来实现骨架公用逻辑
2.线程使用
线程池类自定义
线程池主类
Tomcat中自定义了jdk原生的java.util.concurrent.ThreadPoolExecutor,对应类为org.apache.tomcat.util.threads.ThreadPoolExecutor。
关于jdk原生线程池主类的介绍参考美团技术博客:Java线程池实现原理及其在美团业务中的实践。其中图四描述了任务调度流程。
而Tomcat的自定义子类重写了execute方法的部分逻辑:
|
|
这里Tomcat针对原先已经触发拒绝策略的节点,做了再尝试往队列中塞任务的操作。
所以结合我们的业务,如果有必要,也可以自己实现ThreadPoolExecutor,通过execute方法可以定义我们需要的执行逻辑。
队列
任务队列:org.apache.tomcat.util.threads.TaskQueue。
这个队列类中也有自定义逻辑,比如写入任务的offer方法:
|
|
自定义的TaskQueue中维护了一个submittedCount计数字段,用来表示提交到队列中的任务量,所以最后一个if判断可以到达的前提就是:提交量大于了当前线程池的线程数,在这种情况下再判断,如果线程数还没到达最大线程数设置,就创建新的线程。
当然,业务中我们使用队列时,针对这种默认无界的情况,我们建议根据场景来设置一个容量,防止堆积过量请求造成OOM。
线程工厂类
线程任务工厂类:org.apache.tomcat.util.threads.TaskThreadFactory。
这个类主要是一个工厂模式的简单实现,内部维护了例如namePrefix的字段,方便Tomcat在创建线程时定义名称前缀。
线程模型
Tomcat中针对不同的任务使用不同的线程组,比如:
Acceptor线程组负责连接请求Selector线程组负责I/O 事件监听- 专用线程池负责业务处理
不同类型的任务使用不同的线程组,是我们业务实践中也遵循的原则,这样隔离了互相之间的影响(配置、运行时状态),也提高了任务处理性能。
3.合理并发容器
LifecycleBase中使用CopyOnWriteArrayList维护了生命周期事件监听器LifecycleListener列表。这类对象创建后状态基本不会发生变化,所以使用这种为读多写少优化过的并发容器可以大大提高性能。
这里有我实际用到的例子:有一个服务负责维护SKU原数据,而这类数据经过配置后,改动的频率特别低,当时第一版的缓存设计就是使用了CopyOnWriteArrayList。
4.延迟写
一般我们把网络传输、磁盘读写视为相对消耗性能的动作。因而针对这种操作,服务端代码都会采用「延迟写」的策略。
我们看看org.apache.tomcat.util.net.NioChannel中的write方法,这里就会调用写操作。
而使用到write的地方都会进行buffer缓冲,以此来减少系统调用,这是一种延迟写的思路,我们在各种技术组件中都可以看到这类使用方式。
5.提高锁的使用效率
缩小锁的范围
在synchronized本身已经针对竞态做了无锁->偏向锁->轻量级锁->重量级锁的优化基础上,Tomcat在工程实践中尽量缩小了锁的范围,比如org.apache.catalina.core.StandardService的方法startInternal()负责启动Service相关的子组件:
- Engine
- Executors
- Connectors
|
|
这里的例子中,并没有在整个方法上加锁,而是将锁的粒度细分,来synchronized对应的成员变量,在多线程并发执行时,无需在方法维度等待,只有在访问同个成员时才需要进入线程同步逻辑,提高了并发执行效率。
使用无锁技术
以org.apache.tomcat.util.threads.LimitLatch为例,这个类负责了AprEndpoint网络组件中的连接数限制功能。
其内部的计数成员count使用了AtomicLong类型,底层使用CAS的实现,减少了线程切换上下文的成本,提升并发性能。
成员sync则实现了aqs中定义的共享锁接口,内部排队使用了aqs中实现的CLH队列,相比加重量级锁,队列技术可以提高并发性能。
6.使用堆外内存提高IO效率
以AprEndpoint为例,这个端点组件实现了APR协议相关功能。
APR(Apache Portable Runtime Libraries)是用 C 写的 Apache 可移植运行时库,为应用提供了跨平台的系统接口。
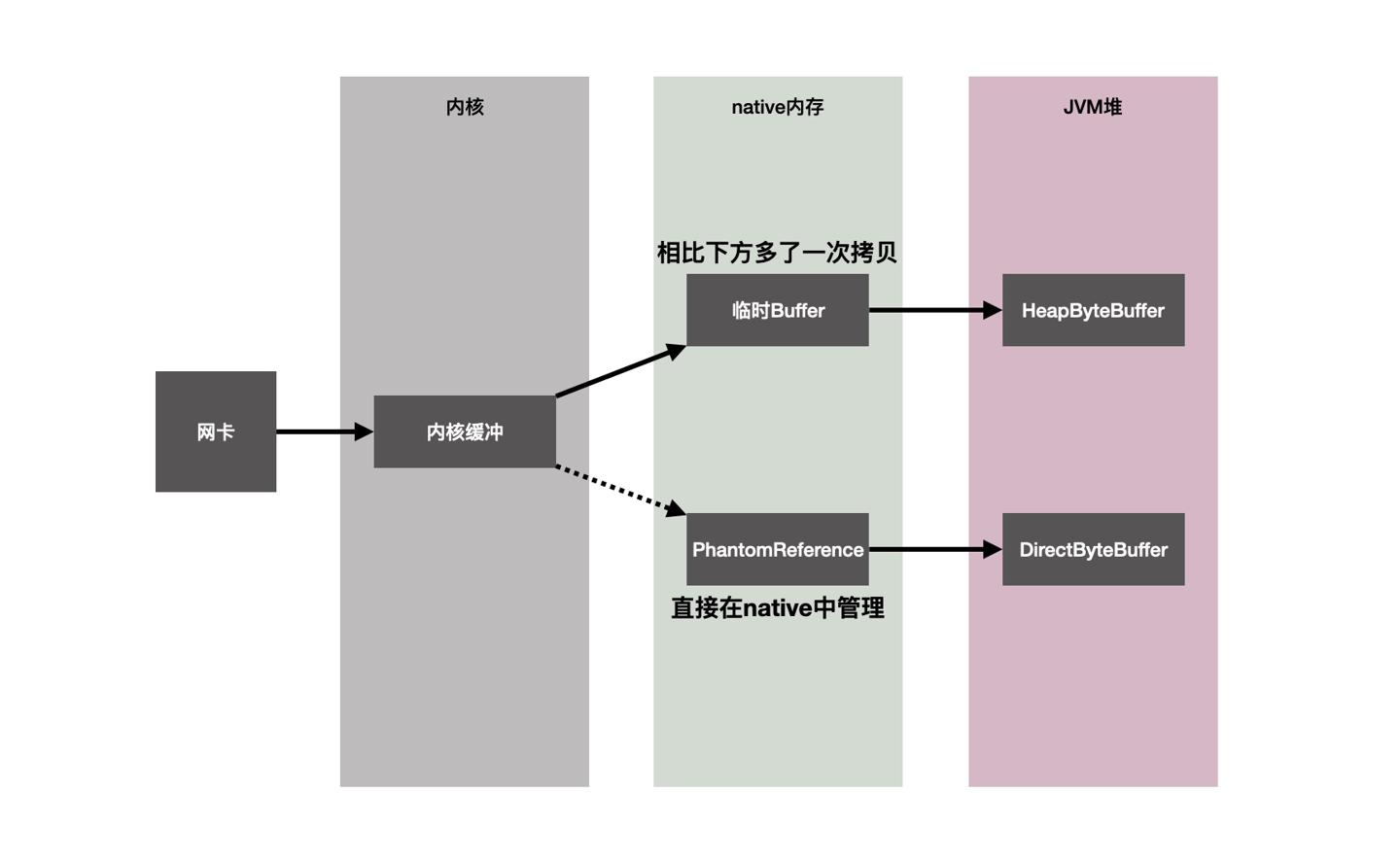
首先NioEndpoint使用Java提供的 NIO 接口实现非阻塞IO模型,而AprEndpoint则使用JNI调用C库,底层使用堆外内存提升网络IO性能。
我们关注下这部分涉及的几个关键类:
org.apache.tomcat.jni.Socket实现网络连接JNI相关接口。org.apache.tomcat.util.net.SocketWrapperBase封装了网络socket涉及的(模板方法)通用操作,比如连接过程的关键动作(生命周期)、连接基本信息设置。org.apache.tomcat.util.net.SocketBufferHandler管理IO过程读写使用到的buffer,IO过程涉及数据传输,过程中通过buffer来存放以及操作数据。这里可以通过参数指定具体的buffer实现类,可选:HeapByteBuffer对象分配在JVM堆上,对应的数据byte[]同样在JVM堆上管理,网络IO过程中,需要先将内核数据拷贝到一个临时的native内存中,再从这个native内存拷贝到对应的byte[]。这里的原因简单可理解为如果直接从native区域拷贝,JVM碰到GC时对象数据会进行移动,对应buffer可能失效,最终这里的限制可理解为JVM的一个权衡设计。具体可参考R大的解释:Java NIO中,关于DirectBuffer,HeapBuffer的疑问?。DirectByteBuffer对象本身分配在JVM堆上,而对应的byte[]则直接位于native内存。成员中的long address记录了native内存地址(映射的作用)。因此相比HeapByteBuffer,数据拷贝少了一次,因此效率更高。
org.apache.tomcat.util.net.AprEndpoint.AprSocketWrapper该类继承自SocketWrapperBase,构造器中主要初始化了数据拷贝对应的SocketBufferHandler,其中direct传为true表示使用更高效的DirectByteBuffer进行数据拷贝,同时创建了负责ssl连接的sslOutputBuffer,同样使用ByteBuffer.allocateDirect创建DirectByteBuffer实例,使用native内存拷贝提高ssl的执行效率。
这里我大概画个图,说明从网络中传输数据的关键流程、组件,以及对比下两个ByteBuffer的区别:
7.使用零拷贝技术
Tomcat作为一个Http-Server最常见的一个应用场景是:为客户端提供静态文件。
客户端调用接口后服务端操作分两步:
- 从磁盘加载文件
- 将数据传给网卡
传统的做法如下图:
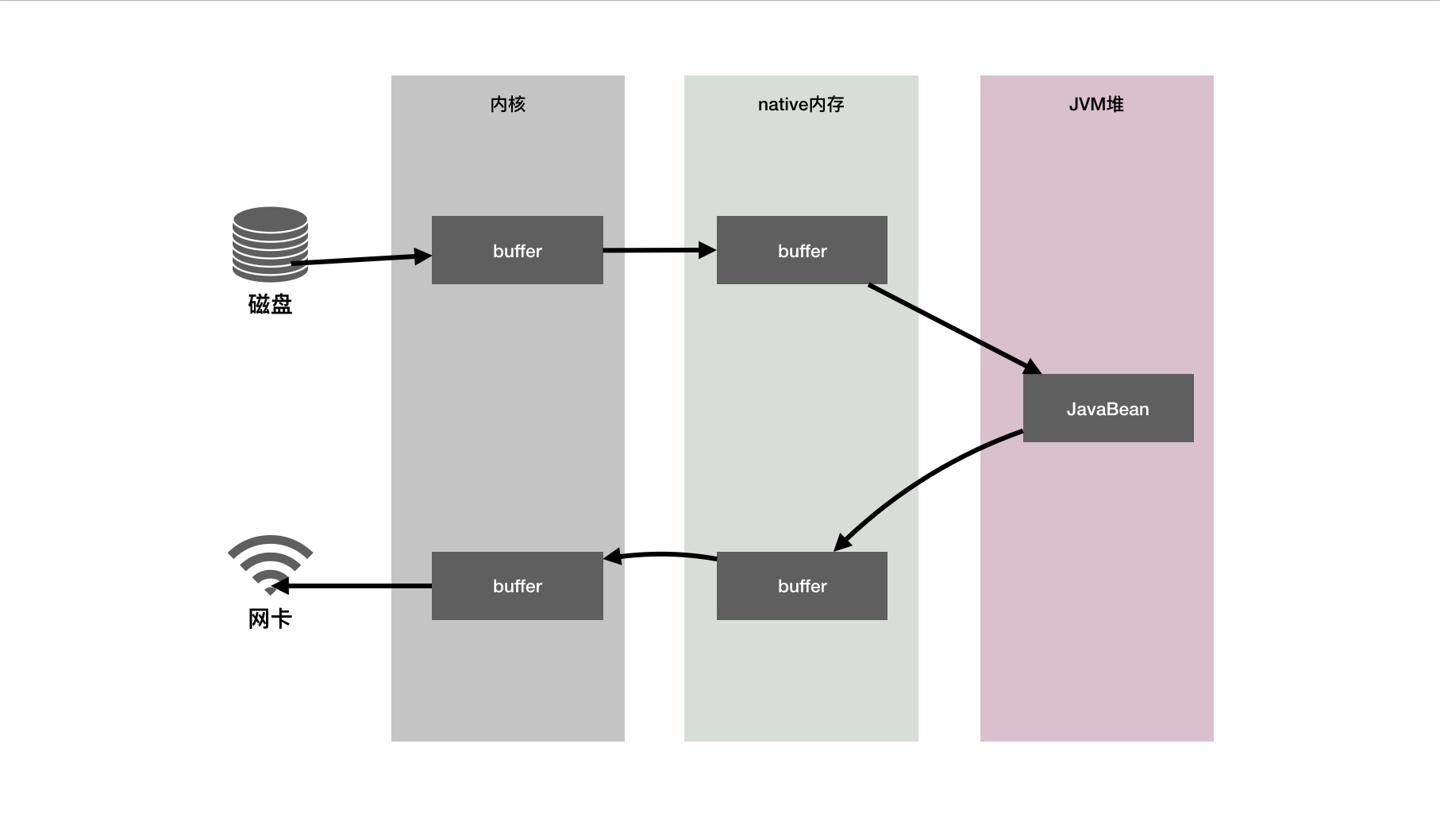
可以看到这个过程一共有六次拷贝数据操作。对应到org.apache.catalina.servlets.DefaultServlet中的doGet方法,跟下内部的调用逻辑,发现最终调到了copy(WebResource resource, ServletOutputStream ostream,Iterator<Range> ranges, String contentType)方法上,其中就做了读取磁盘文件,写到web层输出流中,返回的时候就是把数据扔到了网卡上。与我们上述图描述的一致。
而AprEndpoint中的processSendfile表示底层通过sendFile的方式使用了零拷贝技术:
|
|
可以看到其内部是一个native方法,这里同样是JNI调用,使用了系统提供的零拷贝特性,对应的过程图如下:
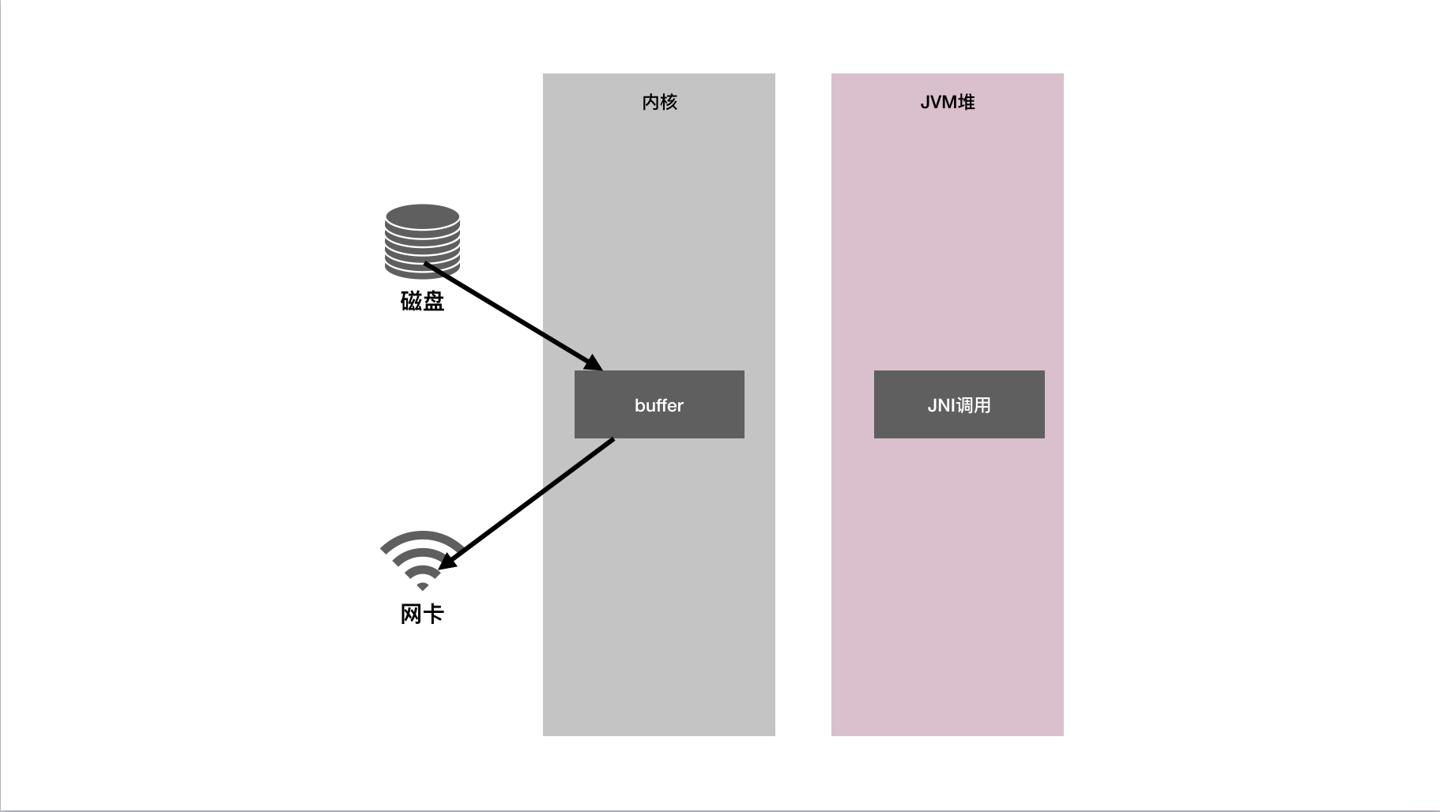
从磁盘到网卡,传统的复制过程我们可以看到一共有六次拷贝动作,并且伴随着内核态到用户态的切换,这里有着比较重的CPU以及内存开销。而sendFile零拷贝的过程,我们只需要一次JNI调动,只需要两次拷贝动作(磁盘到内核buffer,buffer再复制到网卡),从次数上减少了四次,并且无需切换用户态。性能大大提高。
8.自定义ClassLoader
Tomcat利用JDK提供的类加载器机制,自定义了一套类加载逻辑(重写loadClass()),核心类结构如下图:
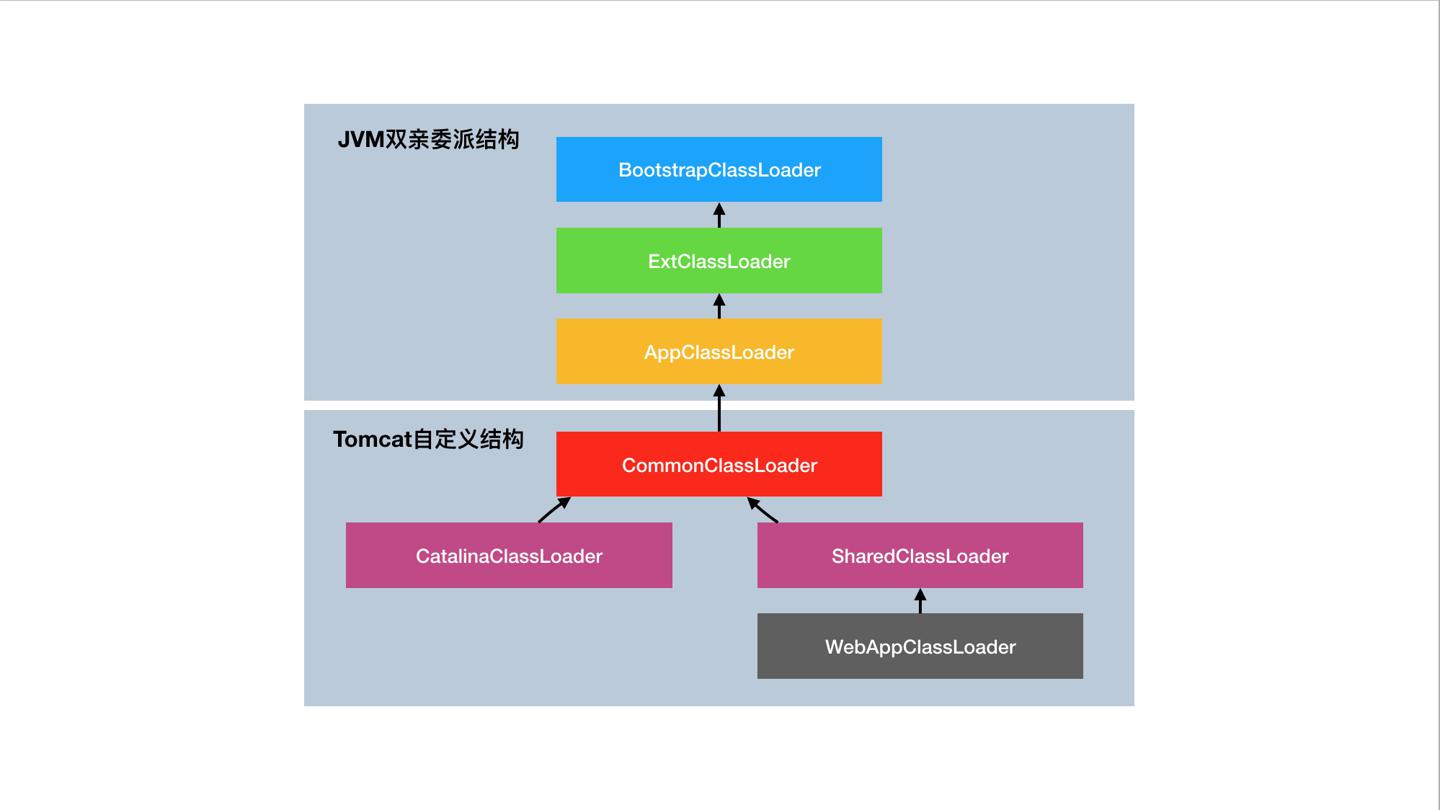
- BootstrapClassLoader:加载 JVM 启动时所需要的核心类,比如rt.jar、resources.jar。
- ExtClassLoader:加载\jre\lib\ext目录。
- AppClassLoader:加载 classpath。
- 自定义类加载器,用来加载自定义路径。
在org.apache.catalina.startup.Bootstrap这个启动类中,如下片段可以看到上述结构图中的几个层次成员,均为WebappClassLoader实例:
|
|
创建了几个不同的实例的主要考虑是:各自管理不同的目录(如createClassLoader传入不同的路径配置)。路径关系:
- CommonClassLoader
/common/* - CatalinaClassLoader
/server/* - SharedClassLoader
/shared/* - WebAppClassloader
/webapps/ /WEB-INF/*
而加载逻辑均定义在WebappClassLoaderBase.loadClass(String name, boolean resolve)中:
|
|
加载过程
0.2中尝试用ExtClassLoader的逻辑主要是基于安全考虑,部分沿用了双亲委派的逻辑:JRE中的核心类会通过ExtClassLoader委派给BootstrapClassLoader加载,防止了应用中自行加载类名与核心类或者ext中冲突的类。
而自定义的逻辑中,主要是增加了本地目录、缓存查找的功能。
隔离机制
Tomcat在线程级别,即Context层提供了隔离功能,即多个web应用使用独立的WebappClassLoader实例进行加载类,这样可以保证多个应用间同个Servlet类同样可以正常加载。
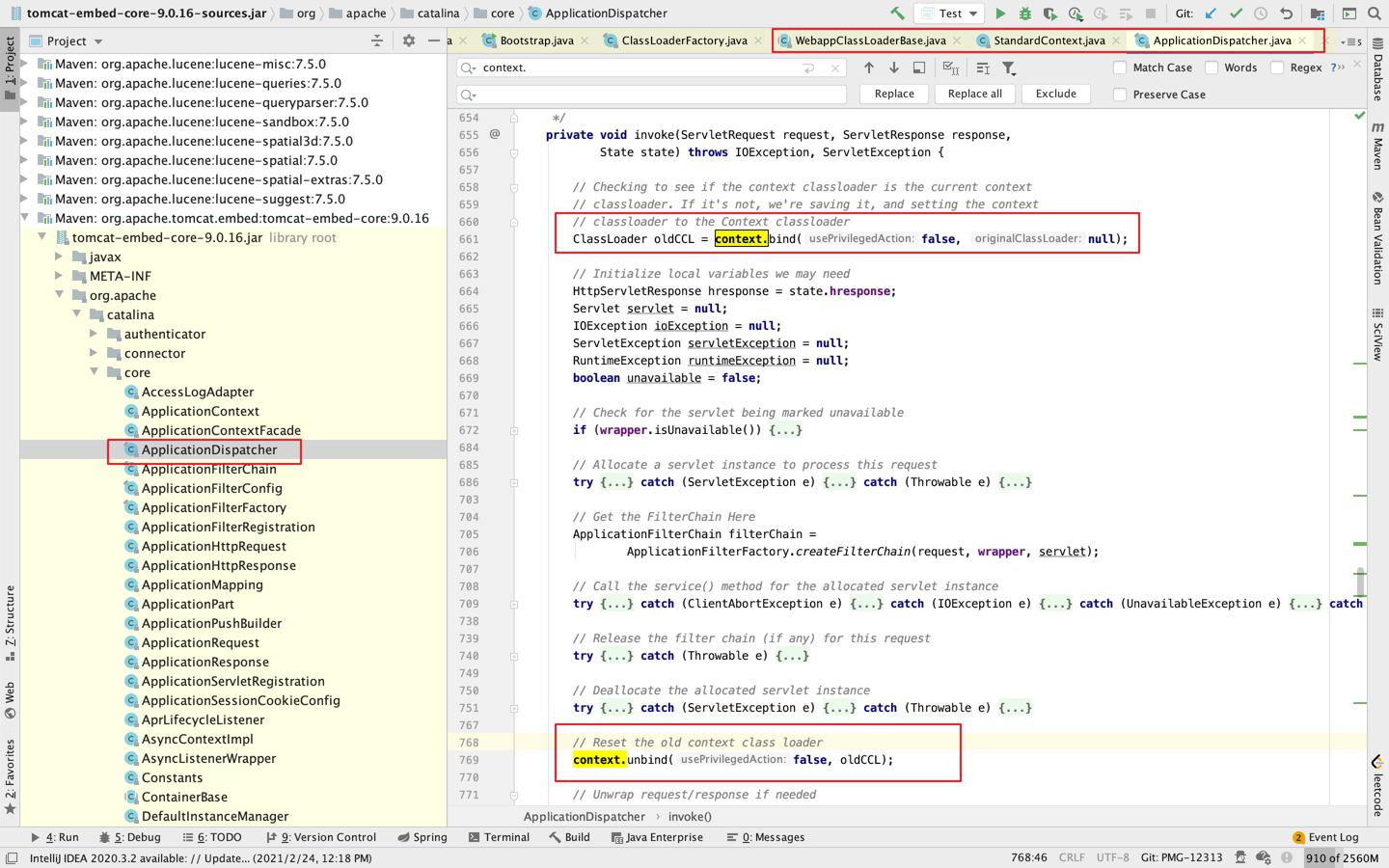
每个context创建的时候内部线程会进行类加载器绑定:
|
|
同样context处理完也会将加载器切换为原线程上下文加载器。
这个过程我截了下源码的图:
而针对共用类库,比如两个web应用使用到了同个框架,那我们的jar可以共用,通过SharedClassLoader实例管理的<Tomcat >/shared/*目录来存放共用的jar。
而针对Tomcat与应用的隔离,通过CatalinaClassLoader实例管理的<Tomcat >/server/*目录来专门管理Tomcat本身的类。
如果是Tomcat与应用共用的类,则通过SharedClassLoader实例管理的<Tomcat >/shared/*目录来共用。
类加载小结
通过以上设计,Tomcat自定义了各部分类加载的逻辑,通过WebappClassLoader几个实例分别管理了多个目录下class文件的加载,也达到了应用间隔离、容器应用隔离、容器应用共用的设计目的。
9.热加载与热部署
Ref: