分析排查一则接口超时问题,定位为JVM Young区新生代过小引发GC频繁、触发STW停顿过多。
背景
| 系统关系 | b服务调用a服务接口x,接口超时。我负责a服务。 |
| 业务场景 | 其中b服务业务场景是B端营销活动场景,存在类似抢购的操作。 |
| 时间 | 2022-10-13 |
| 特征 | 调用端接口超时;偶现(大约一天出现两次); |
| 机器配置 | 传统化机器套餐:标准型S4X6(4 cores cpu 6G mem);我们的服务配置的是4GB堆,500MB元空间; |
| Linux版本 | 3.10.0-862.14.4.el7.x86_64 |
| Java版本 | 1.8.0_181 |
| 服务QPS | 低峰:20*9;高峰 70*9; |
第一次简单排查
首先排查了一遍常规日志,没有明确结论。
尝试在b服务侧增加了redis缓存。
之后几天没有同样的报警。
第二次排查
2022-11-01 同样的接口出现了超时。
晚上八点出头,同事看到GC出现了1.79s的收集停顿时长。
于是,2号上午开始埋头排查:一定要查出个究竟。
JVM参数解读
完整参数:CommandLine flags: -XX:AutoBoxCacheMax=20000 -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled -XX:+CMSScavengeBeforeRemark -XX:CompressedClassSpaceSize=528482304 -XX:+ExplicitGCInvokesConcurrent -XX:InitialHeapSize=4294967296 -XX:+ManagementServer -XX:MaxHeapSize=4294967296 -XX:MaxMetaspaceSize=536870912 -XX:MaxNewSize=1073741824 -XX:MaxTenuringThreshold=6 -XX:MetaspaceSize=536870912 -XX:NewSize=1073741824 -XX:OldPLABSize=16 -XX:-OmitStackTraceInFastThrow -XX:+PrintCommandLineFlags -XX:+PrintGC -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCCause -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintPromotionFailure -XX:-UseBiasedLocking -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:+UseFastAccessorMethods -XX:+UseParNewGC
:+UseParNewGC 使用了ParNew收集器
:MaxHeapSize=4294967296 堆最大4GB
:MaxMetaspaceSize=536870912 元空间最大 0.54GB
:MaxNewSize=1073741824 young区最大1GB
:MaxTenuringThreshold=6 young区对象晋升到old区age阈值
:MetaspaceSize=536870912 元空间 0.54GB
:NewSize=1073741824 young区1GB
:OldPLABSize=16
上面提到停顿了一秒多的gc log
2022-11-01T20:08:44.272+0800: 49.429: [GC (Allocation Failure) 2022-11-01T20:08:44.272+0800: 49.429: [ParNew: 764866K->43858K(943744K), 1.7194357 secs] 834581K->377754K(4089472K), 1.7195128 secs] [Times: user=6.91 sys=0.20, real=1.72 secs]
2022-11-01T20:08:45.992+0800: 51.149: Total time for which application threads were stopped: 1.7198275 seconds, Stopping threads took: 0.0000787 seconds
定量分析
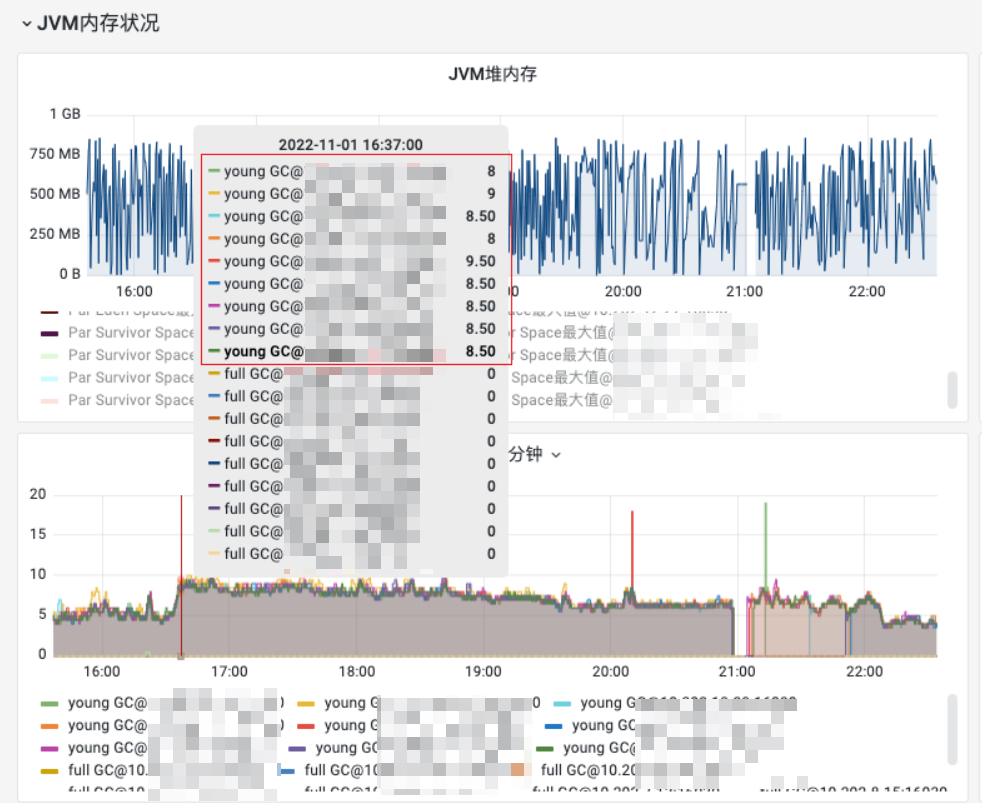
重新描述问题:2022-11-01T20:08:44.272+0800: 49.429 时间点发生了 1.7198275s 的STW停顿。
同时,我跑到对应机器上把一秒前后的log拿下来,使用 gceasy 查看内存分布:
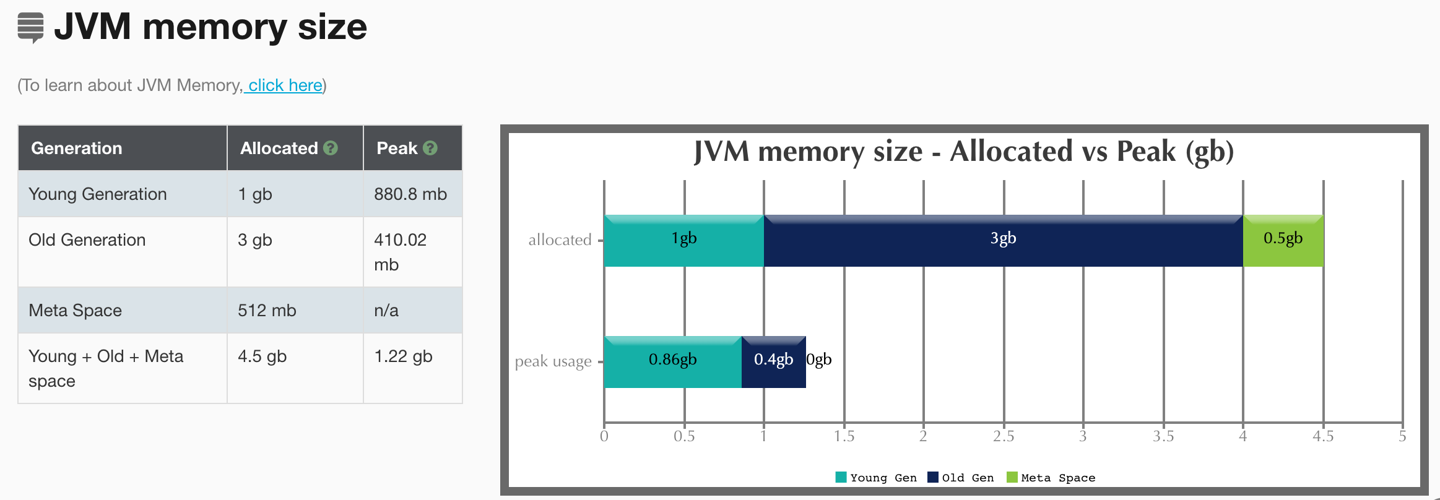
可以看到元空间与old区空间完全够,而young区接近满的状态。
严谨起见,我们将监控时段拉到25号-3号,查看jvm old区内存峰值占用情况:
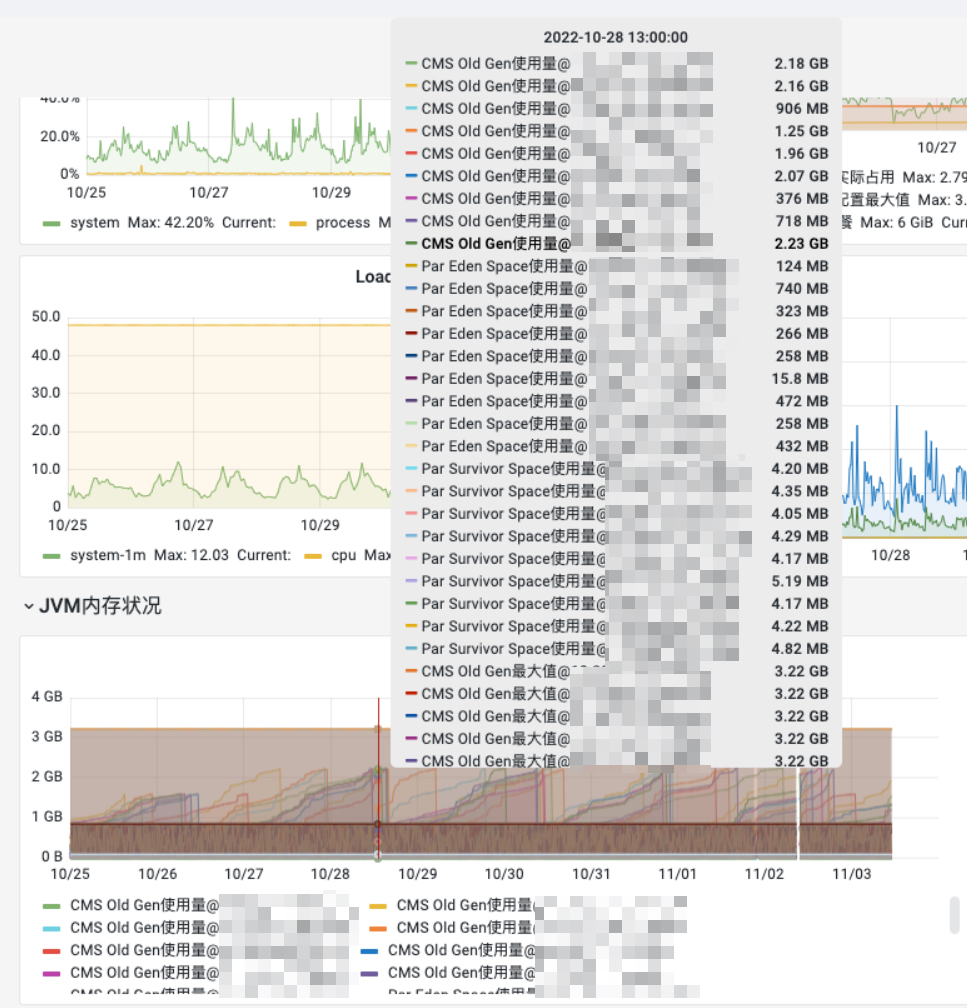
old区谷值占用情况:
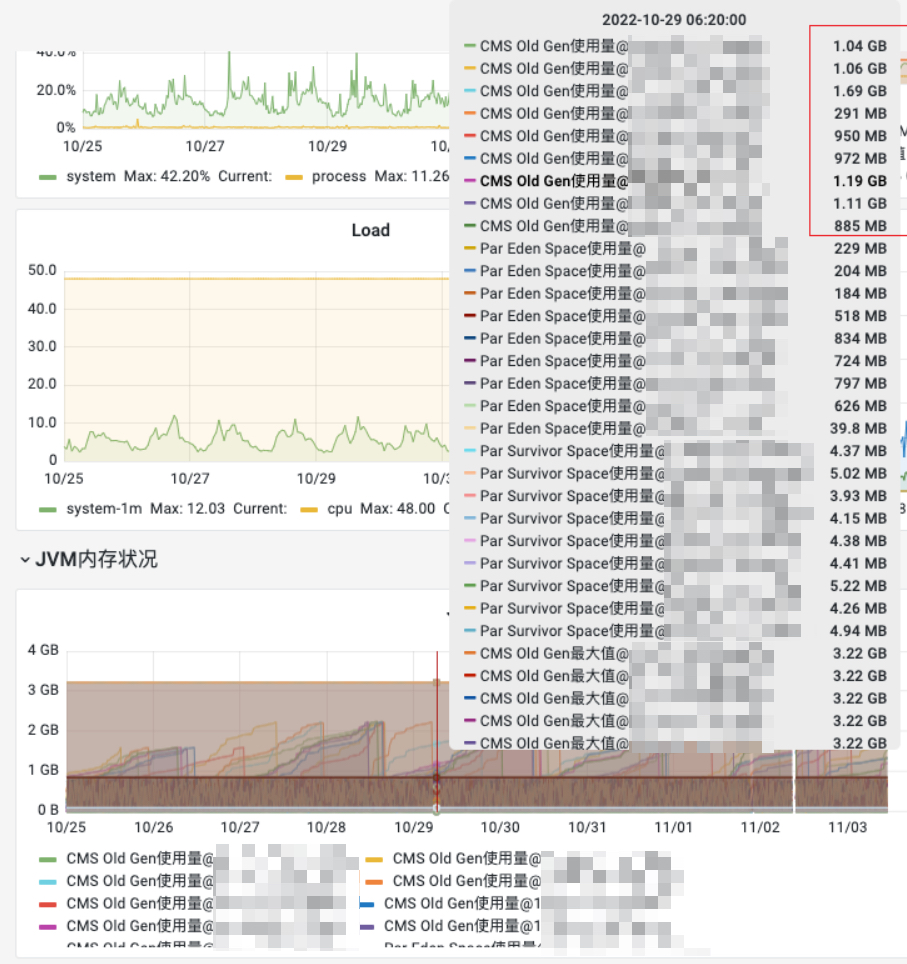
可看到所有实例堆最大配了4GB,其中1GB左右被young区使用,而old区内存最多分配2GB出头,gc回收后仅占用不到1GB。说明我们的实例对象大部分生命周期都不长。
目前其实已经得出一些定量结论:我们服务中大部分对象的生命周期并不长。
查看监控大盘上的jvm信息
本着严谨的态度,我们需要做一些定性分析。
定性分析
大盘上对应出问题实例jvm内存:
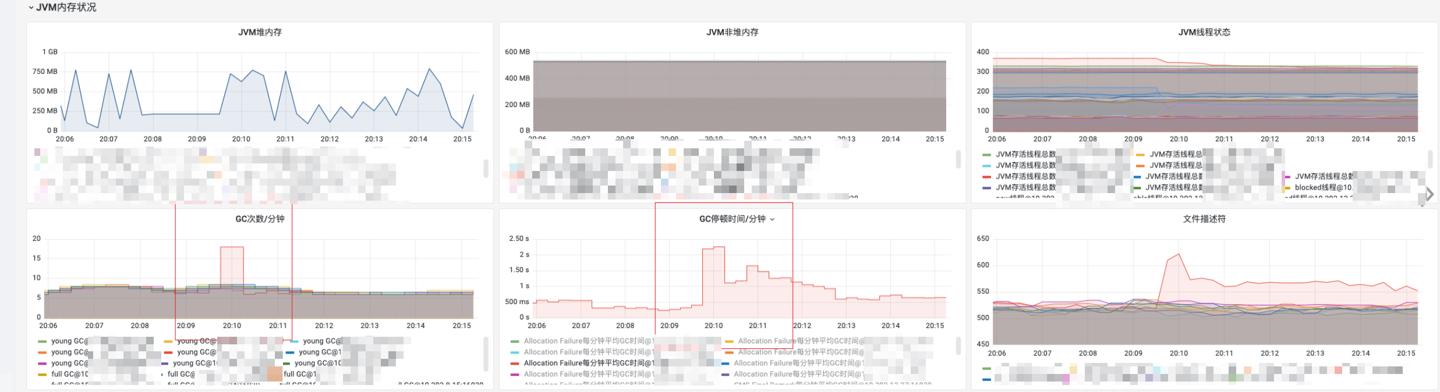 这里的秒、毫秒级别略有偏差,原因可能是监控取的是近似值(统计值)。
这里的秒、毫秒级别略有偏差,原因可能是监控取的是近似值(统计值)。
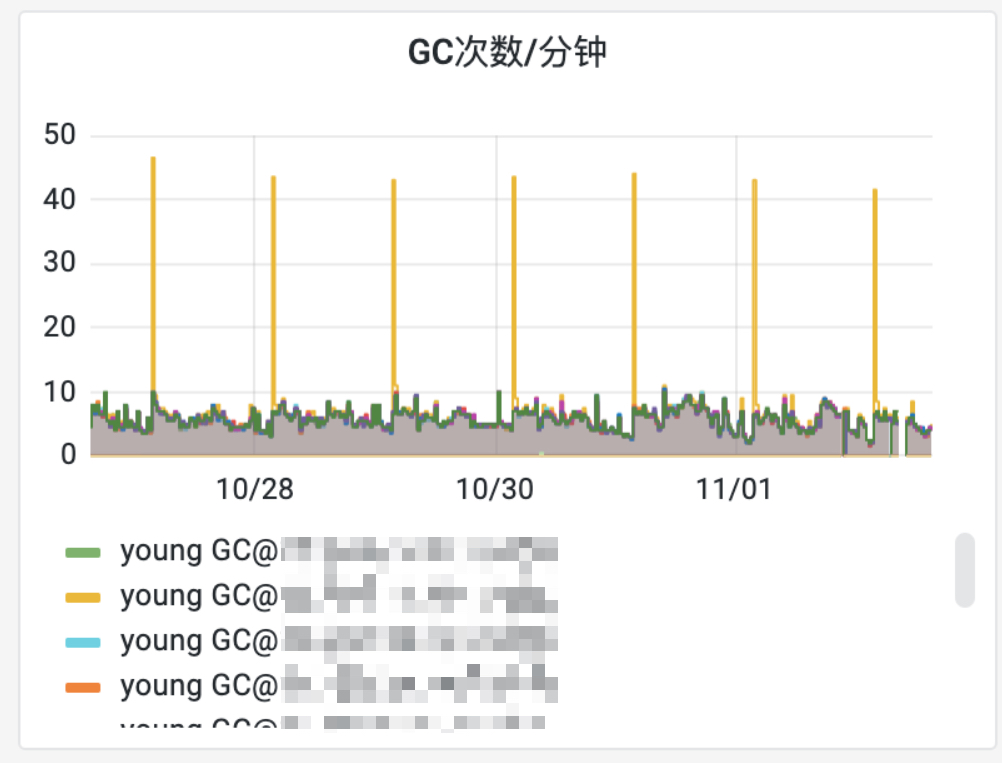
可以看到gc次数相对较稳定,但是在8、9、10分时略有上升,将时间跨度拉大后,这里就是一个突刺。
 无
无fullGC,触发的都是youngGC,并且会有突刺、上升趋势。
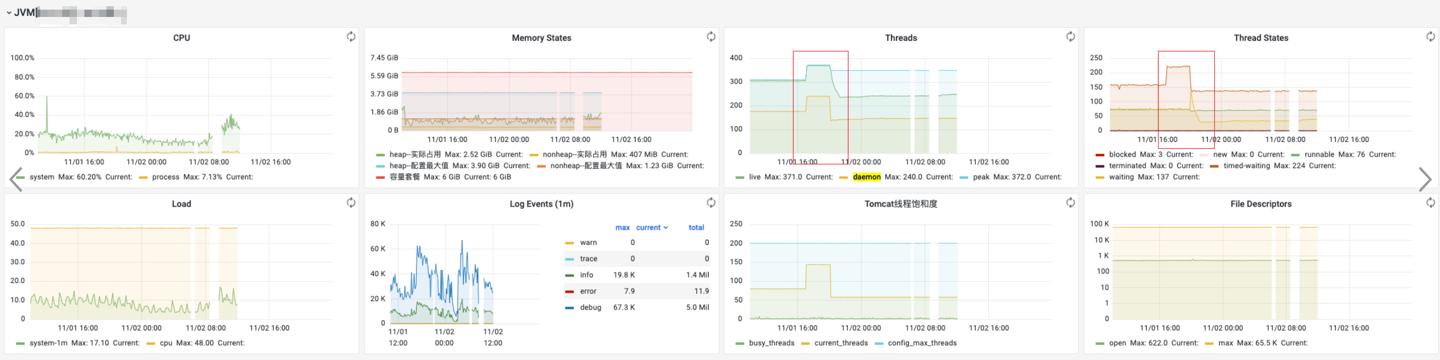
观察线程状态:
结合每分钟gc次数:
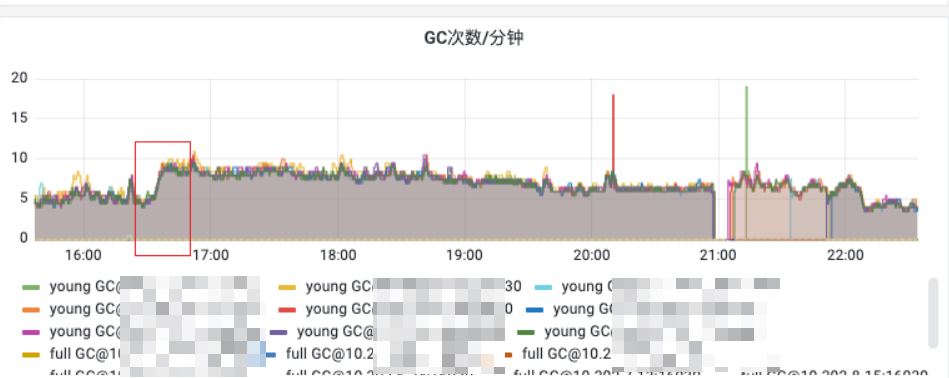 可以发现在监控
可以发现在监控 16:34 开始gc次数变多,曲线攀升一直持续到 16:37 ,此处从5升到了8.5/9次每分钟。
定量分析
三四分钟的时间,每台机器上的gc次数都近乎翻了一倍,激增。(gc次数频繁)
疑点:到底是哪些线程变多?
上面观察线程状态的趋势图,可以看到deamon thread变多。
我们需要研究下这里的后台线程究竟是哪部分的。这里我用arthas观测了线程分布,以及配合分析了qps趋势。
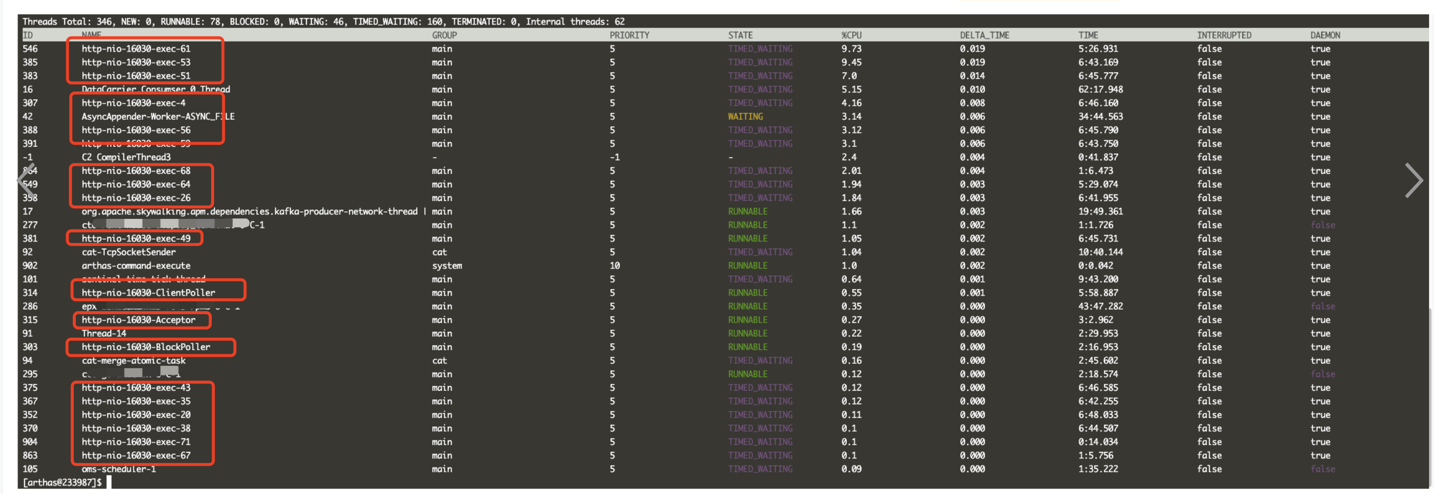 利用平台提供的
利用平台提供的arthas工具,看了下线程分布,可以看到大多数daemon线程为http-nio,即都是tomat在处理http请求。
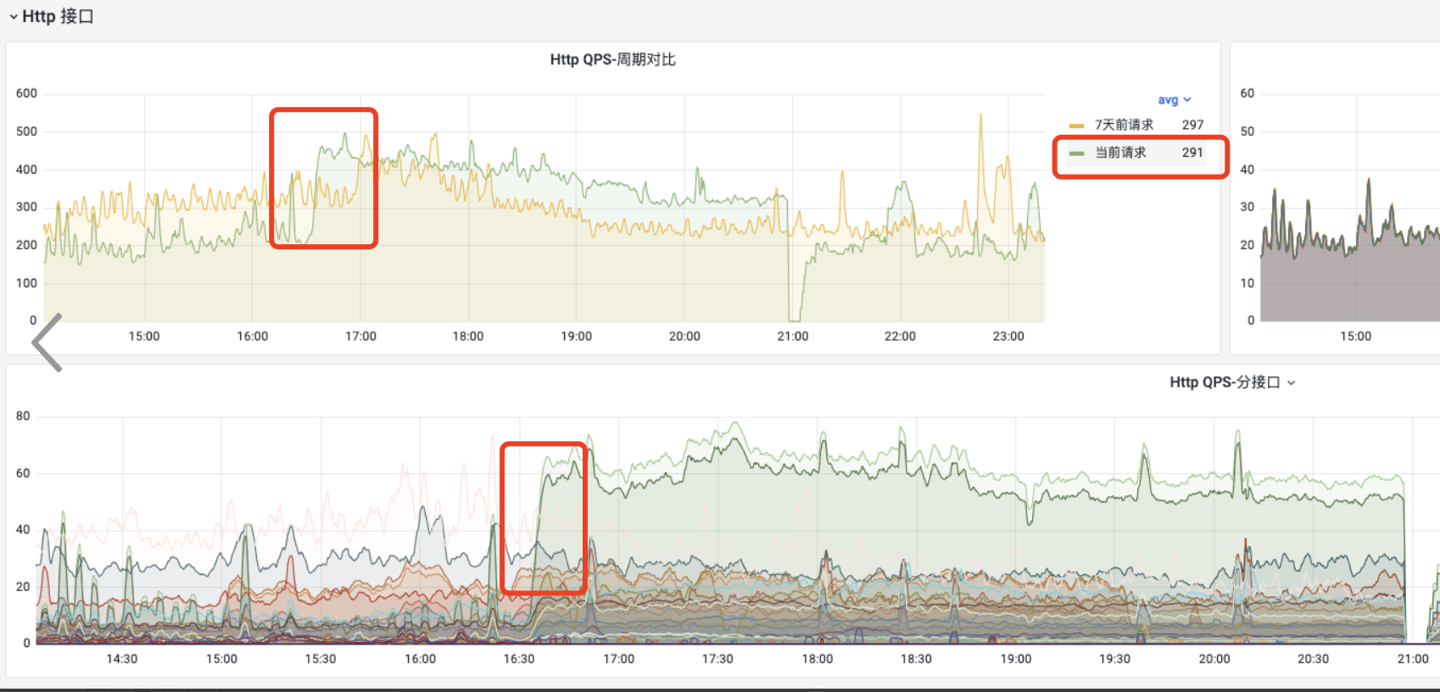 配合观察四点多时段的
配合观察四点多时段的qps走势,可以得出结论:此时由于qps爬升,请求变多,tomat启动了更多了nio线程。
这部分线程我最开始怀疑是gc线程,查阅资料后,发现可以确认,young区parnew回收器使用多线程复制算法,并且以STW的方式运行,其线程数可通过命令确认:
|
|
这里在我们服务机器上输出:
|
|
所以增多的gc线程最多也只有33个,因此,这里线程数的提升主要是tomat nio线程。
附一个知识点:
Parallel New (ParNew) Collector (invoked by “-XX:+UseConcMarkSweepGC” option) The ParNew collector for Young generation uses the “Copy (also called Scavenge)” algorithm parallelly using multiple CPU processors (multiple threads) in a stop-the-world fashion.
The ParNew collector for Young (new) generation uses the same algorithm as the PS collector, except that it has an internal ‘callback’ that allows an old generation collector to operate on the objects it collects (really written to work with the concurrent collector), as described by Jack Shirazi in “Oracle JVM Garbage Collectors Available From JDK 1.7.0_04 And After”. The ParNew collector for Young generation can be identified in GC log messages with the “ParNew” label, as in this example: “ParNew: 1068K->63K(1152K)”. In JVM 9 and older releases, the ParNew collector for Young generation can be invoked explicitly using the “-XX:+UseParNewGC” option. But this option has been removed from JVM 10.
疑点:加内存为什么能解决问题?
这里主要是需要扩大young区内存,前面分析得出,我们服务中的大部分对象生命周期都较短,因此需要扩充young区。
一次Minor GC,主要分两步:
T1(扫描新生代)T2(复制存活对象)
其中 T2»T1,复制成本更高。
当扩大了young区后,Minor GC频率会变低,触发Minor GC更晚后,此时需要复制、晋升的对象就变少了,因此节省了T2的成本。
整体而言,这里会提升性能。
具体细节可参考:从实际案例聊聊Java应用的GC优化 。
疑点:使用G1的优势与条件?
经过综合评估,我们最后将堆调成了8GB,同时切换CMS为G1。
前提:
使用G1有一个前提:堆不能太小,堆如果太小,会出现频繁full GC。原理简单来说,就是实现G1算法需要额外的空间占用(维护关系、状态、对象年龄…),如果堆太小,则对象迅速堆满堆空间触发full GC。
优势:
- 网格化,精细管控
G1对空间进行了网格化,每个网格叫region,默认是2MB,分配、回收空间在region的粒度上操作,将处理链路打散,各自处理各自内部的逻辑;- 类比:就像存储领域的分区,数据根据路由key存到某个分区、分片上,存储系统整体的拓展性、性能、稳定性都得以提升;也很像疫情防控,出现阳性只封控对应楼,而不是一下子把整个区封掉,网格化管理更加灵活;
- 并行回收
- 多线程并行处理,充分利用多核机器的优势
- 年轻代动态调整
- 默认
young区为整堆大小的5%,通过-XX:G1NewSizePercent设定 - 最大可调整到整堆大小的60%,通过
-XX:GlMaxNewSizePercent设定。年轻代回收暂停期间,会计算扩容还是缩容 - 设置了
-XX:NewRatio、-Xmn比例或者大小时,G1会忽略此设置 - 这个特性非常适合我们的服务,整堆大小够用,当较短平快的接口
QPS上升时young区可自动扩容,当长生命周期对象较多时,空间可以让给old区
- 默认
- 控制最大停顿时长
- 通过
-XX:MaxGCPauseMills设定,默认为200ms,大部分应用这个值完全够用
- 通过
- 单独管理大对象
- 大对象不会占用默认的
region,而是使用额外的空间管理,这样彼此不影响
- 大对象不会占用默认的
综上,整体而言,G1在我们有8GB堆的情况下,能够更加动态灵活、分区管理、分离大对象,这些比人工调优更适应线上runtime环境。
因此G1很棒。
结论
目前为止,我们可以得出如下结论:
11-01 16:34开始gc次数变多,gc次数整体一直持续到九点后才出现明显的下降趋势。晚上08:08分出现了二次激增,每分钟gc次数达到了 18 次。- 随着
gc次数变多,jvm内的daemon thread数量变多(用于gc的线程+tomcat nio为daemon thread),业务线程并没有变多。 gc均触发的是young gc,说明业务请求,此时更多的是需要年轻代的空间,即对象生命周期较短。b服务的缓存一定程度上减少了部分打到a的请求量,但是a这一层的进程暂停问题依然存在。young区整体接近满的状态,而日志中出现allocation failure,说明eden区没有足够空间容纳新对象,因此young区整体可以扩大,对应eden区也需要扩大。
方案
基于以上分析,可以有如下方案:
| 方案 | 优点 | 缺点 |
|---|---|---|
| 增加应用实例数 | 可解决此类问题;程序不需要改动; | 消耗云、机器资源 |
增大young区内存 |
可解决此类问题;修改成本小; | |
调整gc collector,从cms调为g1 |
可解决此类问题;G1可以应对更大业务量、低延迟的业务场景;; |
略微更消耗内存; |
各区容量参考算法:
| 空间 | 倍数 |
|---|---|
| 总大小 | 3-4 倍活跃数据的大小 |
| 新生代 | 1-1.5 活跃数据的大小 |
| 永久代 | 1.2-1.5 倍Full GC后的永久代空间占用 |
| 老年代 | 2-3 倍活跃数据的大小 |
小结
- 当前问题通过定性、定量分析,得出了解决结论:
- 增大
young区内存配置 - 或者使用G1,动态智能扩充
young区
- 增大
- npc问题:
network delay、process pause、clock drift一般不容易碰到,碰到此类问题需重视,解决后可提升个人、团队能力。 - 通过case study方式,加以积累,可有效地将问题解决转化为工程师能力、团队能力。
心得:
- 解决问题不能靠猜,需要有理论、数据依据。
- 尝试性方案可以作为逼近答案的方式。
- 知识点需要系统化学习,结合实践加强理解。
Ref
- 自动化回归环境搭建复盘
- What is Daemon thread in Java and Difference to Non daemon thread
- JVM Parameters
- https://stackoverflow.com/questions/13543468/maxtenuringthreshold-how-exactly-it-works
- https://reins.altervista.org/java/A_Collection_of_JVM_Options_MP.html
- https://stackoverflow.com/questions/28342736/java-gc-allocation-failure
- https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/g1_gc.html
- 小米Talos GC性能调优实践
- 从实际案例聊聊Java应用的GC优化
- 工具gceasy
- http://www.herongyang.com/Java-GC/Collector-Young-Generation-Collectors.html
- 关于生产环境改用G1垃圾收集器的思考
- G1 Garbage Collector – Java 9