踩坑事务内循环调用sleep,通过调整线程池参数的方式问题得以暴露。
背景
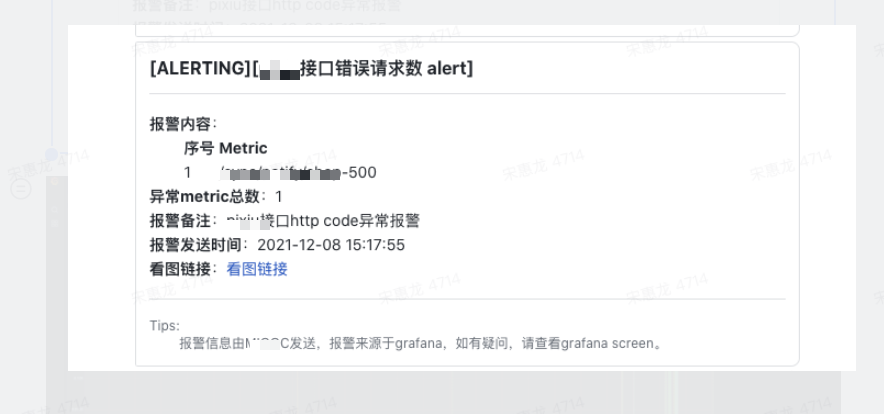
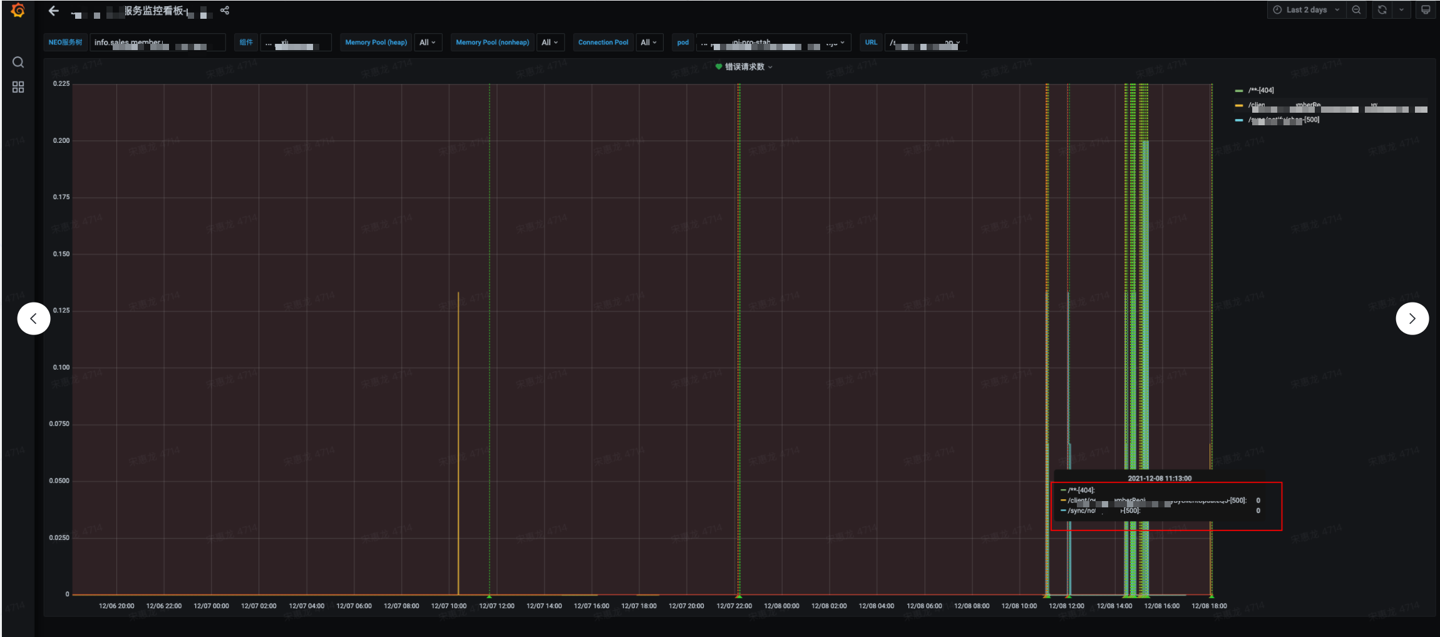
12.07晚我负责的应用发布了一批需求相关的变更,乍一想如上报错接口与那批需求无关。
问题排查
遇到问题首先查具体日志,grafana这里只是告诉哪里有问题,但是应用内部的情况,这里并没有打出来。
定位问题代码位置
可以通过kibana查下打到es中的应用日志:
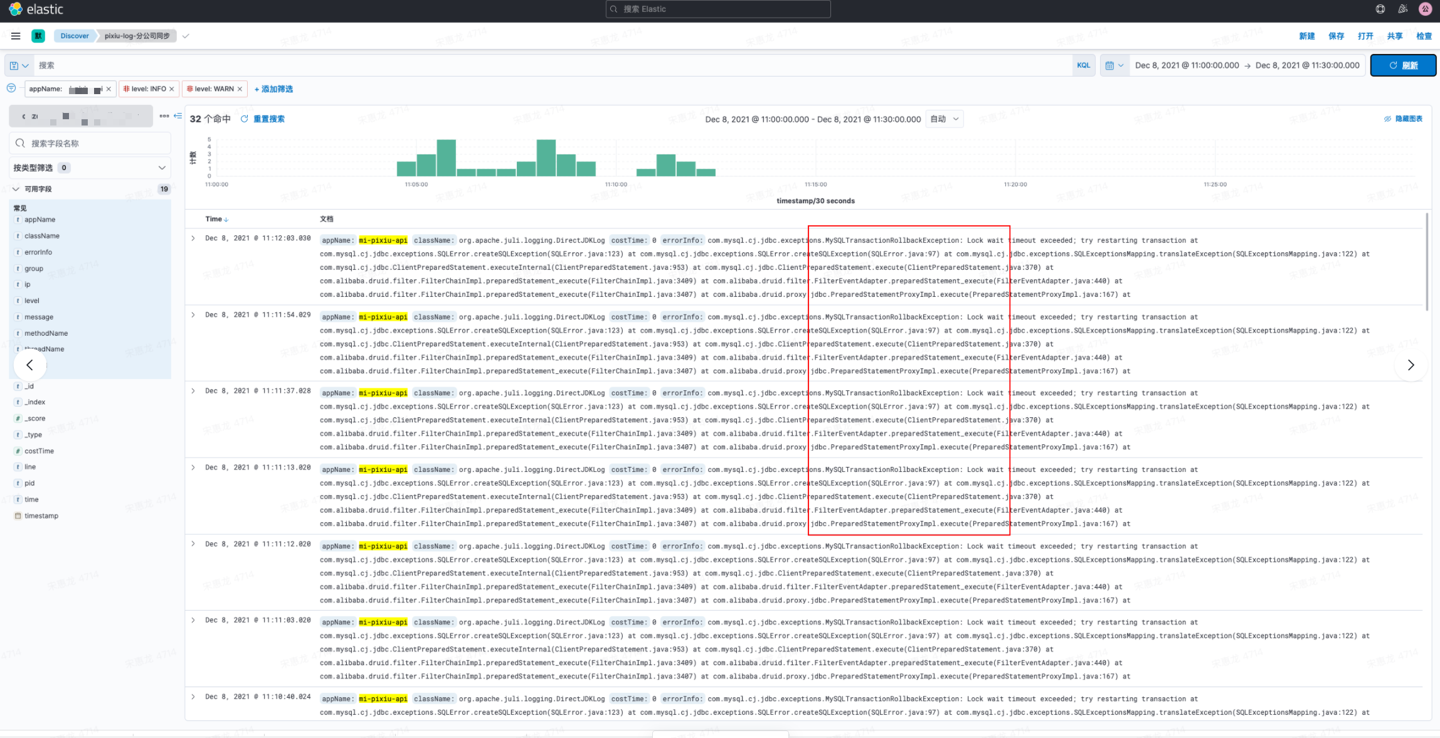
发现对应时段有大量MySQLTransactionRollbackException报错。
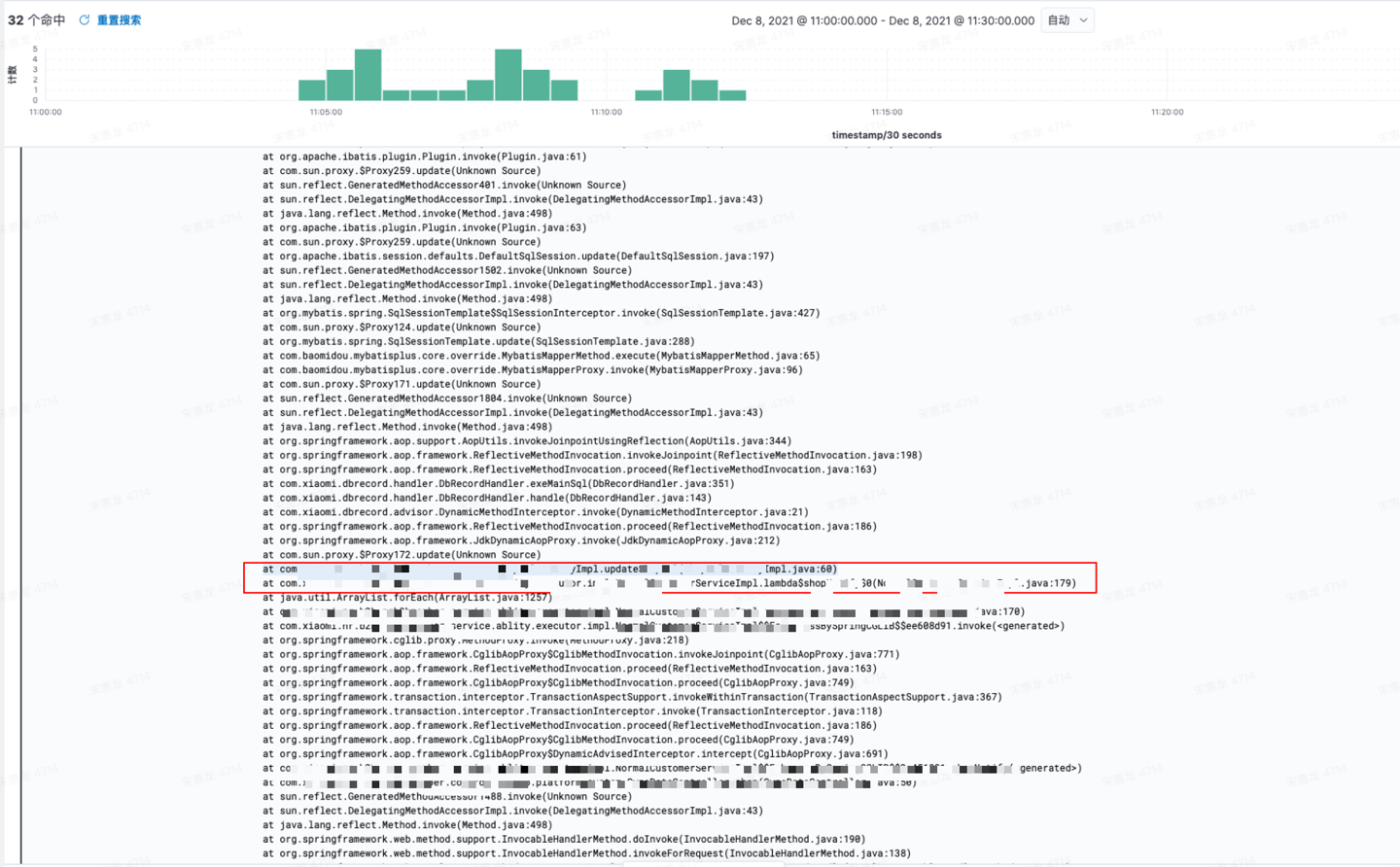 进入异常栈,简单分析可得,这行代码有问题。
进入异常栈,简单分析可得,这行代码有问题。
如果es日志目前还不支持上下文(前后内容)的展示,我们可以通过最基础的方式把相关日志找出来,进终端:
|
|
必要情况下可以多打些内容出来,根据自己需要指定需要的行数。
通过python起个http-server,暴露80端口进行日志文件的下载:
|
|
如图:
日志拿到本地,我们就可以更方便得浏览、分析问题。
分析问题代码
初探
由上可知,A.java:60 这里负责更新A关系表(这里关系到数据库事务锁)。而调用的地方是 BServiceImpl.java:179 a方法,翻开源码(伪代码):
|
|
初步看没有什么问题(跑了好久没问题),发现附近最新的变动来自10.18,我们点进去看看:
发现调用了java Thread的sleep方法(也就是上面的方法b)。这里注释写得很清晰,是为了解决数据库主从延迟的问题,因此这里延迟10s执行。
但是!sleep不会让出monitor的ownership,同时这里业务层加了事务注解,事务持有的锁资源也不会释放。
通过 DataSourceTransactionManager.doBegin() 我们可以看到,本质上spring这种框架是通过java.sql包下的接口与各种数据库进行交互的。
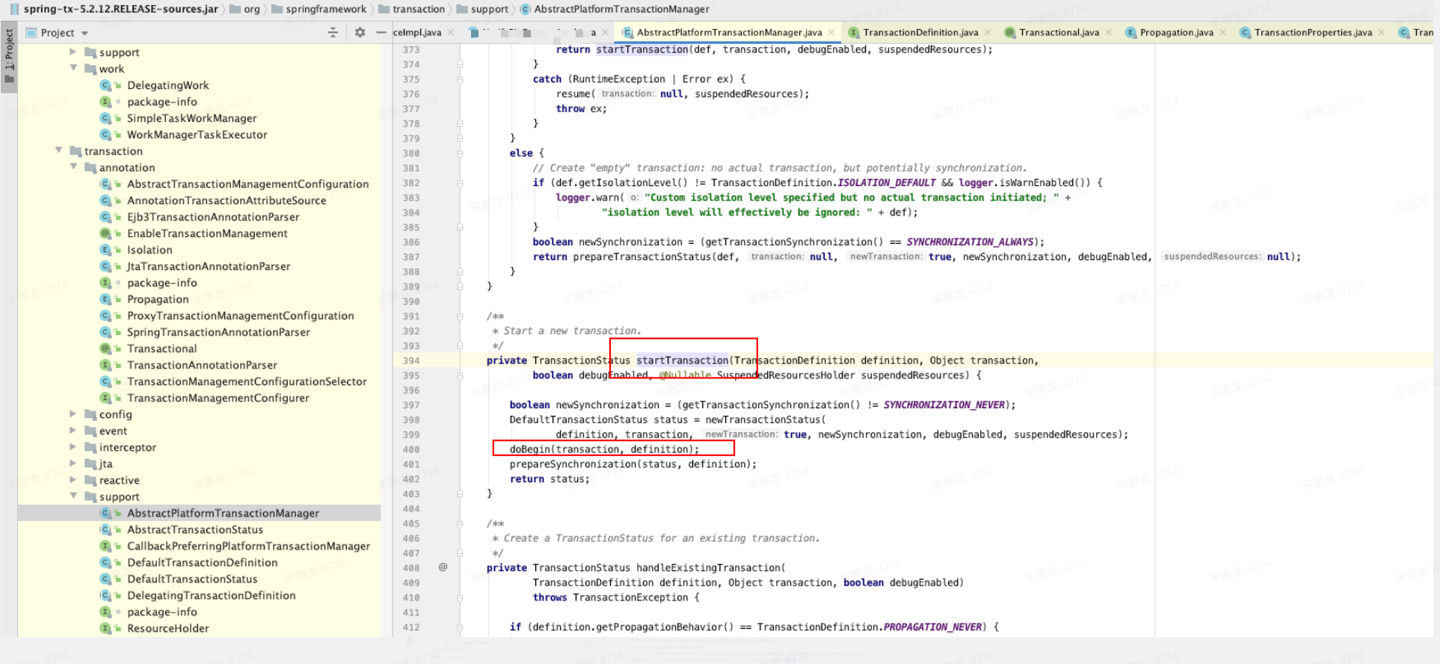
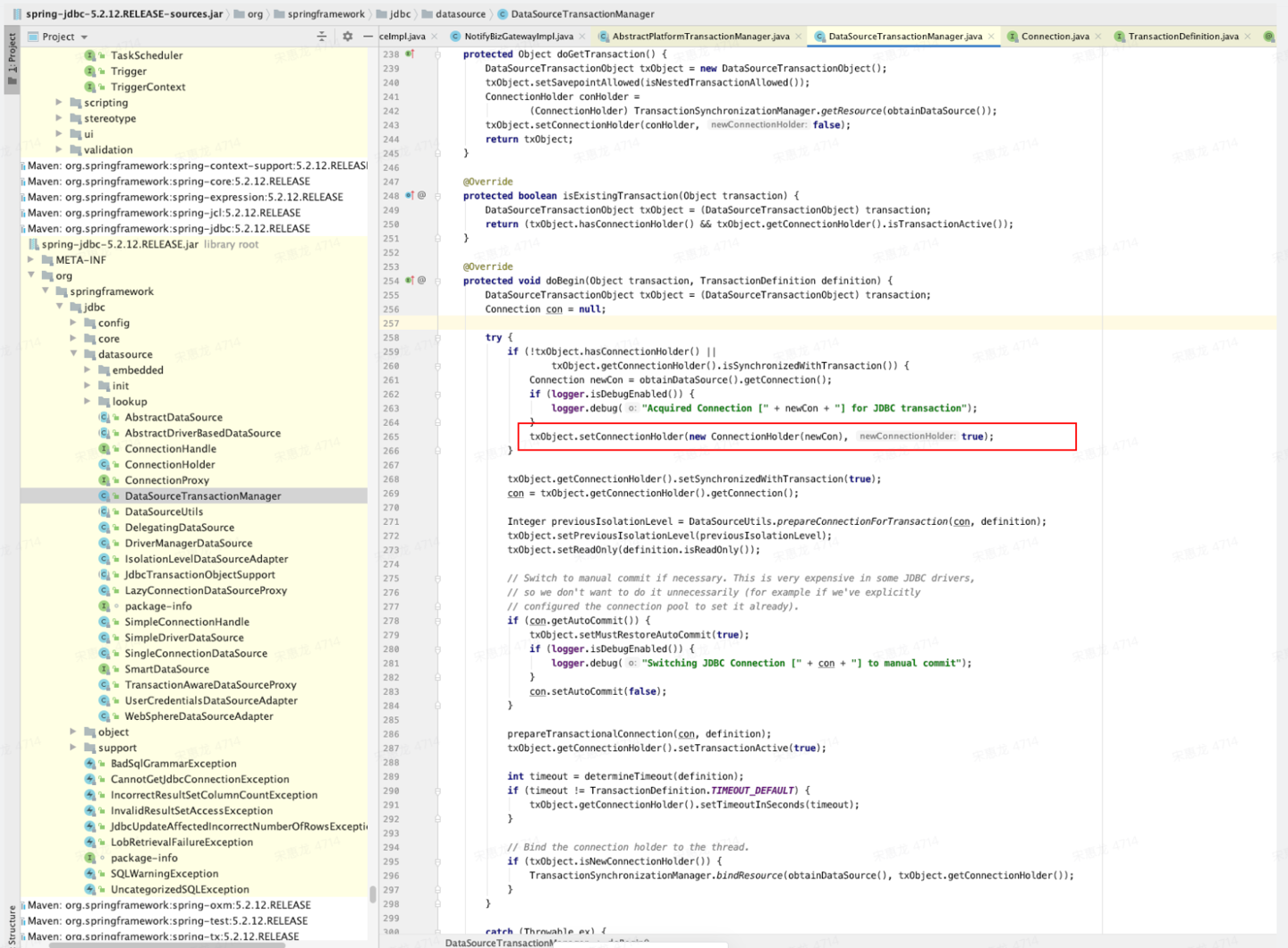
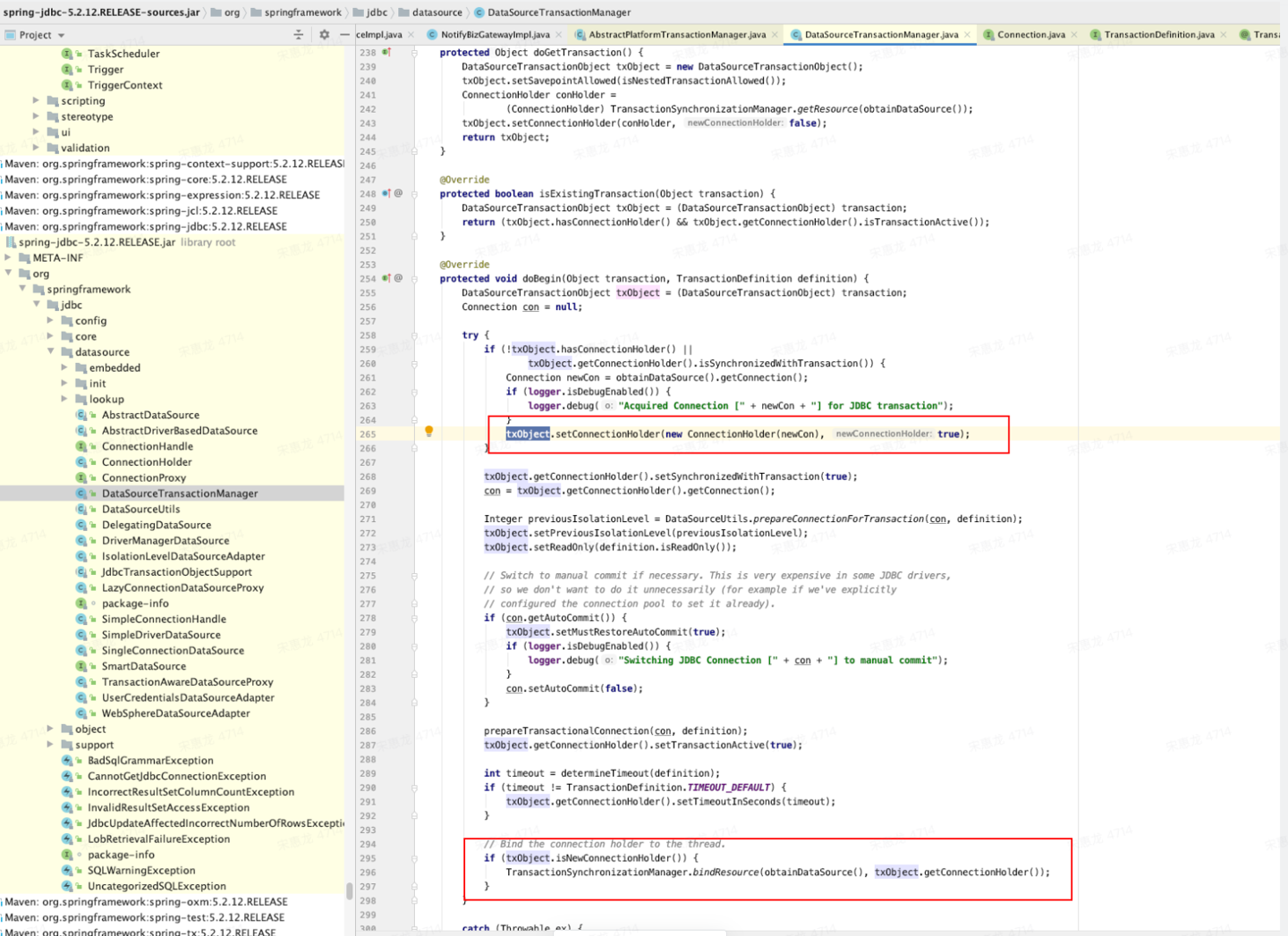
连接、锁资源均绑定到执行当前事务的线程上。
疑点
但是!我们这里的 b() 贴了 @Async注解,这里明明是通过新的线程池去执行的,所以理论上sleep不应该阻塞、占有当前事务线程的资源。
但是巧就巧在,我们在昨天上线的代码里,把默认的线程池配置改了,现在的Executor配置如下:
|
|
线程池coreSize是1,maxSize是5,队列容量指定了200,而拒绝策略指定了callerRuns,这些参数以我对代码的了解(之前不知道发消息的业务中使用了sleep)下经过了预估,预估是可行的。而原先默认的线程池使用了spring默认配置,可参考TaskExecutionProperties,其中coreSize是8,maxSize是Integer.MAX_VALUE,队列容量也是Integer.MAX_VALUE,默认拒绝策略为AbortPolicy,因此原来使用此线程池会不停创建线程进行sleep,通过消耗线程、内存资源将此问题覆盖了。
破案
经过上面对sleep代码的分析,我们目前可知:请求数比较多,并且是循环调用的情况下,线程池200队列长度的限制很快会被突破,业务此时触发CallerRuns策略,回到原线程执行,原线程经过多个sleep10s操作,一直持有事务资源,此时业务方法大概率会超过事务等待时间。
|
|
回到我们上面出错业务方法的代码:
注意req.getShops(),只要这里循环超过六次,这里的循环内的sleep10s累积起来一定会超过innodb_lock_wait_timeout的60s。至此,抛出MySQLTransactionRollbackException: Lock wait timeout exceeded。
问题解决
针对性处理:
- 调整线程池配置,可适当增加队列长度、线程数(根据具体业务调整,并且隔离不同业务线程池)。
- 去掉sleep操作,使用ScheduledExecutorService进行定时、延迟业务的执行。
长期优化:
- 优化上线流程,增强CR。
- 制定编码规范,增加条目:禁止事务中使用sleep这类不释放资源的方法。同时必须使用sleep的时候使用TimeUnit类进行调用。
- 加强、丰富监控告警。