为什么Elasticsearch/Lucene全文查询这么快?
本文要研究的问题:ES/Lucene的索引为什么这么快?
Elasticsearch本质上是基于Lucene增加了分布式高可用管理功能:
- 副本
- 分片
- 集群
而我们今天要研究的,一段数据查的快不快,指的是数据结构以及索引模块的设计。本文暂不探讨es分布式相关的设计。涉及到的数据结构细节描述会使用其他文章进行分析,本文不做数据结构内部实现、过程的分析。
ES的NRT写入过程
首先我们需要了解es提供的near-real-time近实时查询的写入机制。
在es单点中,一条数据写入遵循以下流程:
- 内存
- 第一步写入两个位置
- 写入
in-memory-buffer,此时通过get接口可实时拿到单条数据 - 同时写入
translog,这是es中提供的wal事务日志,保证数据的持久性
- 写入
- 稍后调用
refresh接口写入段文件
- 第一步写入两个位置
- 磁盘文件
- 调用
flush将translog落盘 - 调用
flush将segment落盘
- 调用
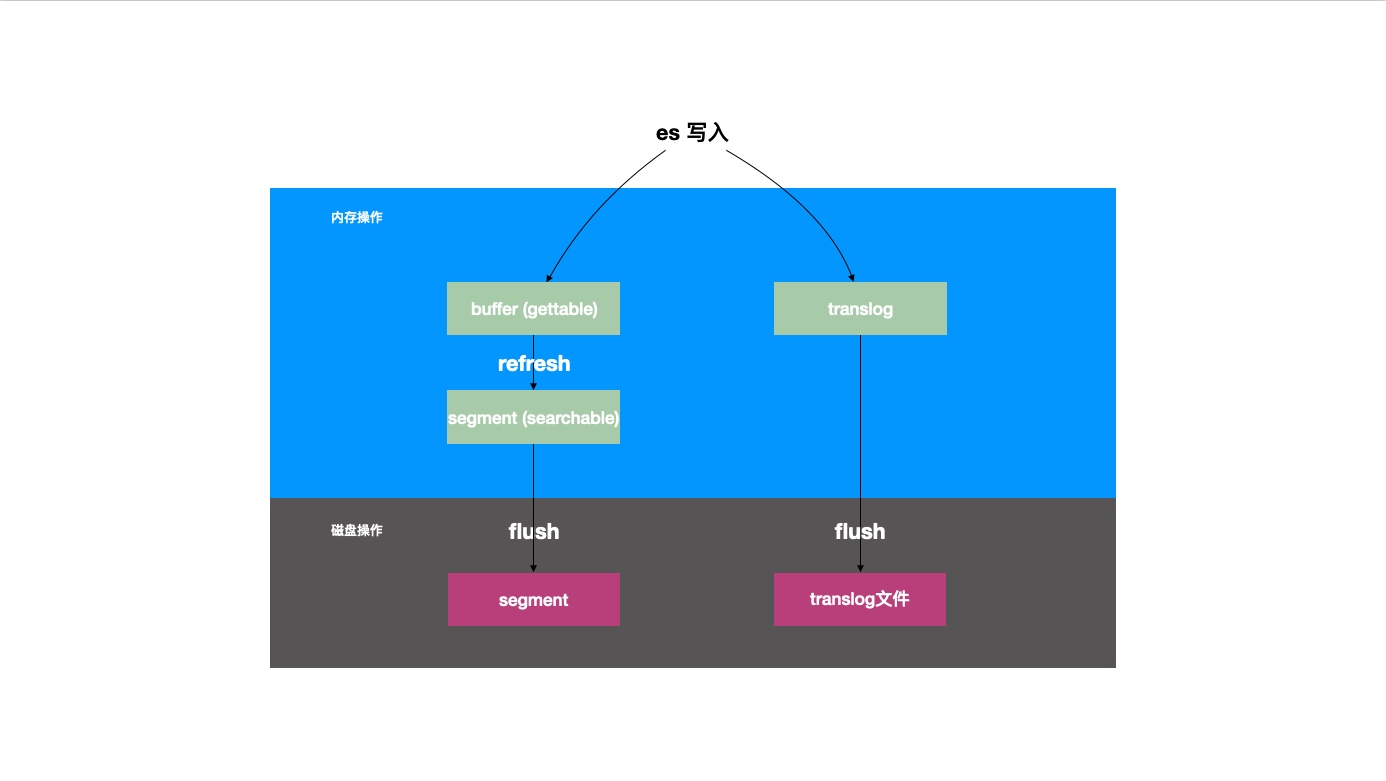
我们今天要研究的索引数据结构,就是为了定位上述的segment。
段segment一旦写入就具备不可变性。immutable的优势在于并发操作的时候无需加锁,并且可以常驻内存,但是内存占用过大的时候这里会是一个优化点。数据新增时创建新的段文件,删除时标记状态,延迟实际的删除动作。
索引设计
全文索引对字段首先要经过分词的处理,也就是把一个字段按照分词的规则拆分成多个词条,前端查询的时候这么多词条都可以命中最原始的写入字段。
我们先写入几条数据:
- id:1 name:a1 age:11 desc:‘1这个人住在广州市琶洲村’
- id:2 name:a2 age:22 desc:‘2住在北京回龙观’
- id:3 name:a3 age:33 desc:‘3住在上海静安寺’
这个结构天然就是一个forward index正排索引,即id直接指向数据行。
一般RDBMS中的索引分两类:
- 聚簇索引 id指向具体行数据
- 非聚簇索引 索引关键词指向id
RDBMS的索引只保留原始的字段值,比如(1、a1、11、1这个人住在广州市琶洲村)。
根据不同的场景,我们可以使用hash-table、有序数组(二分、跳表)、平衡树来完成底层数据结构的设计。
ES索引经过分词,就会在词条term的维度来创建查询key,比如(1、a1、11、广州市、琶洲村、1这个人住在广州市琶洲村)。
ES索引我们叫它inverted index倒排索引,一个segment就是一个完整的索引,包含三个模块:
- Term index
- Term dictionary
- Posting list
按照上述对RDBMS索引的数据结构设计我们同样可以在ES中实现term->数据的查询结构。但是为什么ES使用了目前的设计呢?我们来分析一下:
Posting list
首先Posting list存储了数据的id,拿到id(在这里还有多个词条命中合并的过程)后我们就回到了传统存储系统中查数据的过程。
这里内部使用了跳表结构,支持快速查询(时间复杂度低),并且可以支持多个列表间做交集操作。
Term dictionary
ES中就维护了term词条到Posting list的映射关系,这个结构就叫Term dictionary。
大体上我们可以考虑使用以下数据结构实现Term dictionary:
- map 数据不需要有序写入。但是不支持范围查询。
- 有序数组二分 支持范围查询,数据需要有序写入
- 跳表 支持范围查询,数据同样需要有序,相比数组更吃内存,查询效率高
- B+树 MySQL索引选用的结构
ES分词后的查询key可想而知量是很多的,按照上述的几种结构的设计,我们无法直接把Term dictionary常驻于内存。如果落盘,我们倾向于这几个设计原则:
- 减少查询磁盘IO
- 尽量顺序写
- 遵循数据局部性原理
B+树中通过扩充单个节点上数据的量(n叉)来降低树高度,以此达到了上述1+3点的设计原则。单节点存储更多相邻数据遵循了局部性原理,而控制树高度则有效减少了磁盘寻道次数。
通过选用适当的数据结构,我们可以降低这里查询的时间复杂度,并且可以减少磁盘寻道次数。
Term dictionary实际存储为以block为单位的.tim文件。
Term index
ES在上面思路基础之上做了加速的设计,即:Term index,也就是为查询哪个(哪些)词条所做的索引。
Term dictionary加速了查哪些数据id的过程,Term index加速了查哪些词条term的过程。
与B+树降低树高度来减少磁盘随机IO的策略类似,ES底层使用了一种特殊的特里树trie来进行term的压缩存储,我们叫他FST Finite Status Transducer。
我们首先简单看看特里树的特征:
- 公用前缀 符合ES多词条多重合的场景
- 查询时间复杂度O(n),n表示查询key的字符串长度 时间复杂度很低,查询快
- 问题:实现消耗内存
而Lucene底层使用的FST本质上是一个图结构,相比trie树,增加了公用后缀的特性,同时,使用压缩技术解决了消耗内存的问题。关于FST的设计解析查看这里:关于Lucene的词典FST深入剖析。
读者可使用这个工具创建已知词条集合组成的有限状态机树:Build your own FST。
实际上Term index只会存储term的前缀(再进一步是上述Term dictionary存储block的前缀),效果类似于以xxx开头的数据,一定程度上减少了这部分数据占用的空间,配合FST的压缩设计,使得Term index可以常驻内存。因此内存中直接可以定位Term dictionary的大概位置(.tim文件上的block指针),以此减少磁盘寻道次数。
综上,从Term index通过FST结构,实现了加速定位Term dictionary的位置(反过来也支持fail fast)。从Term dictionary又是一层索引结构,加速了定位Posting list数据id的过程。
存储压缩
数据查询过程快是索引设计的一大目标,而另一个目标则是过程中使用的存储结构占用的内存需要尽可能小。需要在内存占用、IO次数、CPU占用之间做权衡。Lucene中关于数据压缩有以下设计实践。
FOR
关于Posting list中id集合的存储,Lucene从4.1版本开始通过增量编码的方式进行了压缩,术语叫做Frame Of Reference(FOR)。这里我们直接通过图示进行说明:
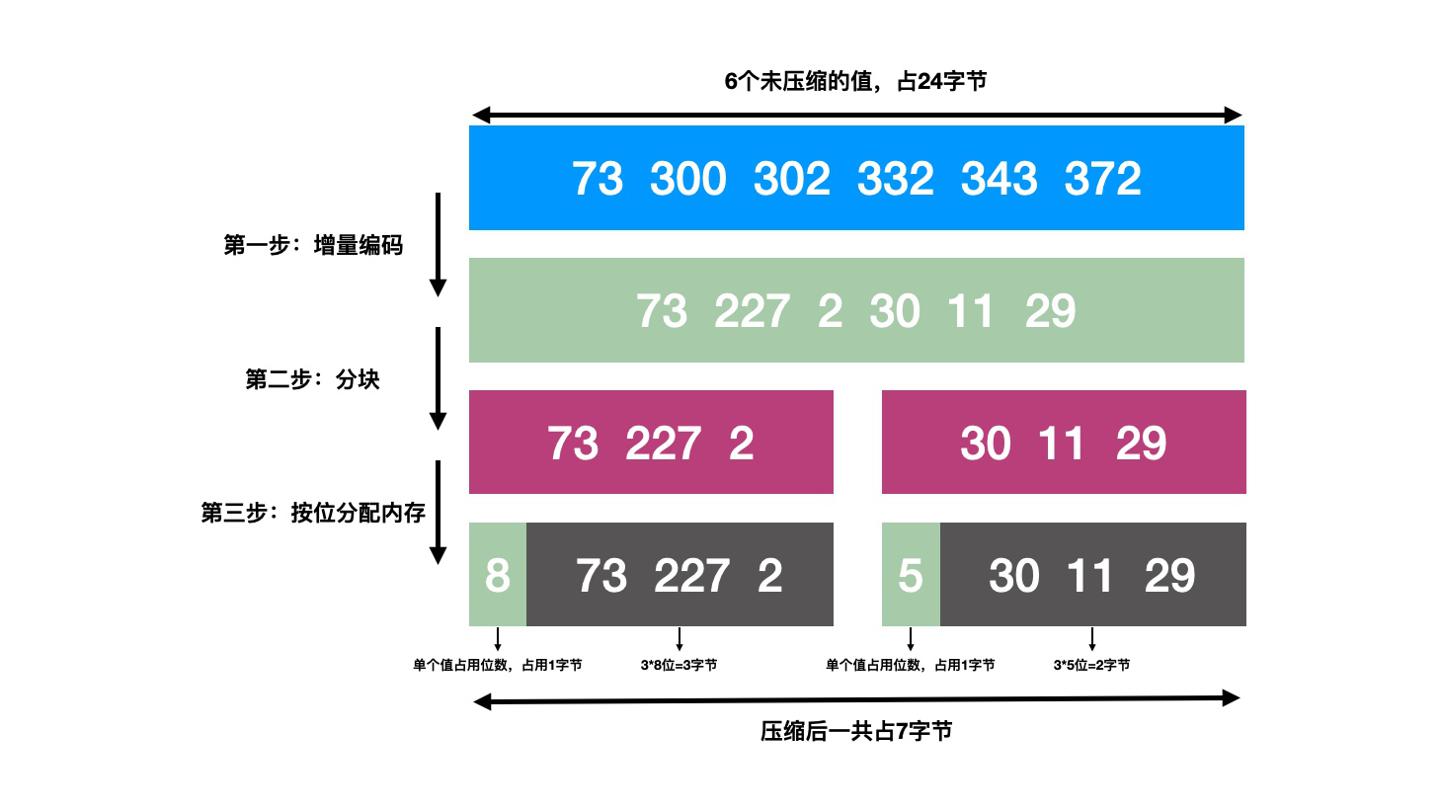
数据经过增量拆解、分块(分组block),然后根据最后分好的组内最大值计算二进制最大所需位数,比如图中的227对应二进制11100011则使用8位空间,图中的30对应二进制11110则使用5位空间。因此增量、分块、按需分配内存可有效做到无损压缩、节约内存。
Roaring bitmaps
对于有序整数id集合(比如filter对应缓存,记录了查询条件到命中docId的映射),Lucene使用咆哮位图Roaring bitmaps进行压缩。
Posting list存储于磁盘,而这里的缓存则直接常驻内存,所以对应的压缩策略也有所不同。由于是对查询过滤缓存所做的压缩,那么编码解码的速度一定不能慢于多执行一次查询的速度,所以这里的编解码一定要足够简单(因为ES很吃CPU,可能没有太多的CPU分配给编解码的任务,复杂任务就会导致编解码过慢)。
Lucene从5版本开始,最终的方案是结合了short数组+位图:
- 数据量少于4096时,使用short(-32768~32767)数组进行存储,此时内存占用比位图更少,遍历使用也很直接
- 数据量多于4096时,使用bitmap存储,位操作是效率最高的指令(编解码效率最高),存储100M文档数据仅需12.5MB内存,相比int数组使用的400MB缩小到了3.125%的大小
这个方案下,无论是查询匹配的docId还是针对多个查询条件匹配id交集,存储与计算效率都很高。
这里画个图来更直观地说明过程:

小结
综上,我们了解到es的写入存在近实时的过程,底层文件存储、数据结构使用了Lucene的实现。
数据查询快,主要是有Term index``Term dictionary``Posting list几个索引模块的加持。而Term index这种常驻内存的结构使用了FOR``roaring bitmap等压缩技术。结果就是省内存、查询数据快。