了解Unix、Linux系统下的进程控制fork函数。
工作中经常会碰到需要研究一下的问题,而这些问题恰好暴露出自己基础知识的不完备,因此博客中对需要「研究」的知识归类成文。
定义
Unix/Linux操作系统提供fork函数,用于创建当前进程的子进程。
返回值
这个函数会返回两次值【区分父子进程】,原因是内核拷贝当前进程形成新的子进程,而在两个进程中都会做出返回动作。
- 子进程返回0,pid0这个在内核中分配给了内核交换进程【特殊值】,所以这里的0表示是子进程返回的,调用方在此返回分支下执行子进程逻辑。同时子进程可以在任意地方调用
getppid()获取父进程id - 父进程返回子进程的id,原因是父进程只能通过这种方式记录子进程id
返回错误
fork调用失败会返回-1,因此调用方需要针对错误进行容错处理。
调用错误的可能原因:
- 进程数超限
- 内核内存紧张
- 系统没实现fork
使用的例子
我们看一下Redis中后台生成rdb文件(rdbSaveBackground)中对fork使用的例子:
|
|
可以看到Redis中是正确处理了fork返回值。
调用影响
fork调用之后,创建的子进程会拷贝父进程的地址空间,包括:
- 堆
- 栈
- 数据
一般来说子进程创建之后,内核通过glibc中的exec函数执行拷贝逻辑(基于execve),这个过程不一定会用到这些数据的全部,也不一定是立刻会用到(修改)。所以考虑到这点,内核提供了COW写时复制的机制。
简单来说
copy on write,就是在修改一块数据的时候,我们才复制一份原数据进行修改(延迟、惰性写),这是这个机制的基本思路。这种思路同样可应用在应用系统设计中。
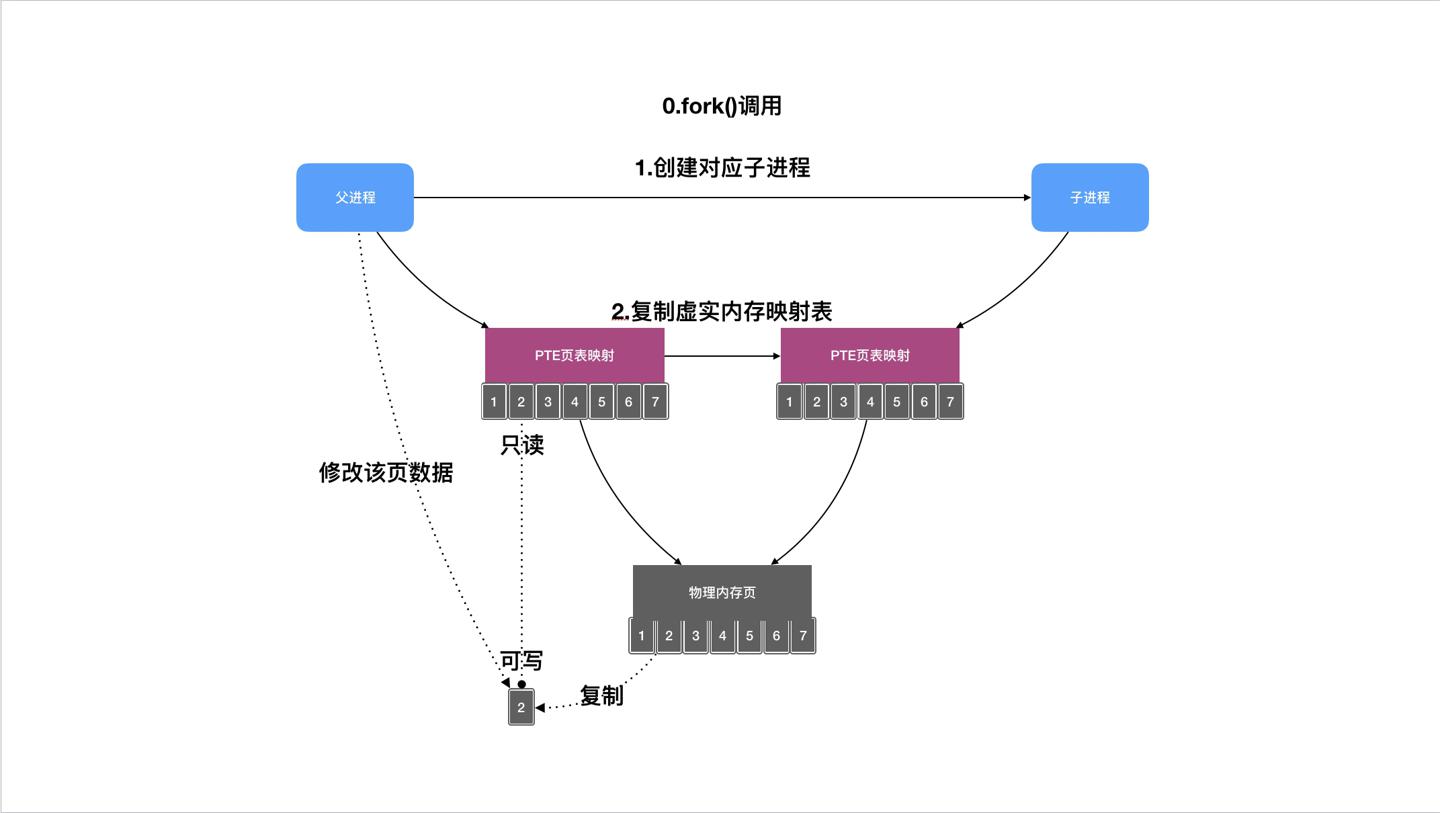
fork调用后子进程会立即持有一份 指向与父进程相同的物理内存页 的页表(PTE:Page Table Entry),页表相对物理内存来说轻量很多。此时如果物理内存页没有发生变化,页表中会标记为只读状态,而一旦父子进程中有一个需要修改物理内存数据,则触发缺页异常(page fault标识数据一致性需要同步)。
页表(
PTE:Page Table Entry)是一个列表,内部维护了每一虚拟页与物理内存页的映射关系。
此时内核就执行COW逻辑:
- 创建一个新的物理页
- 拷贝内容到新的物理页
- 分配父子进程各自的页表
- 页表中页项状态修改为可写(表示这一页更新成最新状态了)
通过上面过程的描述,fork刚刚调用后,只要对应物理内存没有修改动作,则子进程只需要拷贝轻量级的页表,对于调用方来说,性能大大提升。而物理内存拷贝的动作,发生在数据被父子进程修改的时刻,这里才是性能消耗的时候。
到此,我们可以考虑下,比如在Redis中,为什么fork有时候会阻塞主进程(线程)呢?考虑Redis大多数时候作为缓存存储服务,前端的请求量是比较高的,那么fork后数据发生了变化(更新动作),主进程对应的某一页数据就发生了变更,此时就进入了COW拷贝动作的逻辑内。如果此时系统配置了大页(比如1GB),又恰好修改的数据命中到这一页时,拷贝的数据量大阻塞时间就会更久。不过互联网缓存业务中,读多写少,因而这种情况发生概率较低。
因此,我们小结下,fork调用后,子进程立刻持有页表,而拷贝动作的影响大小,取决于父子进程的物理数据是否被修改,这个决定了拷贝动作发生的时刻。
小结
以上,我们过了一遍fork的定义、处理过程、影响。
从这一函数内部的设计中,我们可以学习延迟写COW的思路,在读多写少的场景下,COW可以有效减少没必要的数据复制,提高系统性能。