解答组内技术分享时抛出的一个疑问:buffer跟cache的区别是什么?
背景
目前的团队开完周会后会有一个简单的技术分享环节,本周的话题中主要是同事聊了下Java中的IO流,其中就涉及到了BufferedInputStream、BufferedOutputStream、BufferedReader、BufferedWriter这几个基于buffer数组的实现类。
其中的成员大概长这样:
|
|
那个时候我脑子里突然蹦出了之前与网友们探讨过的一个问题:buffer跟cache的区别是什么?
这几个实现类里面的成员名字叫buffer,那么为什么叫buffer呢?跟我们应用里面使用比较多的cache即缓存有什么区别跟联系呢?
组内解答
大家各抒己见,领导也说了点他的理解:
- 存储结构不同
- 设计意图不同
cache是提前把需要频繁使用的数据都读出来- 而
buffer则是把数据分段分批读写到一个结构中,供之后的计算使用
自己的理解
buffer
buffer中文为缓存区,缓冲存储区,缓冲存储器。
an area in a computer’s memory where data can be stored for a short time
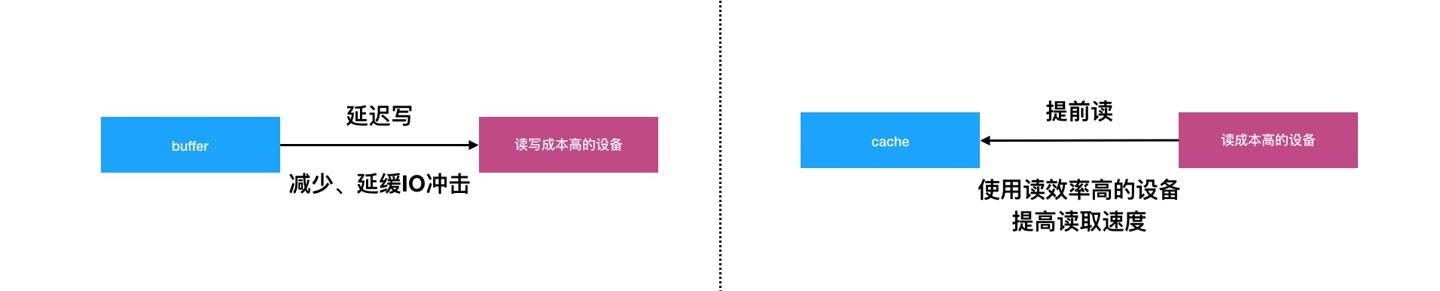
一般是将一些需要使用(读+写)的数据放到内存的一块区域,作为读写动作的中间层,不直接与底层存储交互,以批量、分页的形式将数据归到一个逻辑单位内,减少数据与磁盘、网络等设备的频繁IO次数。是一种延迟写思路的实现,这里的写泛指读写动作。
结合生活中的例子,比如工位离垃圾桶很远,那么我们可以放一个小一点的垃圾桶,等小的垃圾桶满了之后统一扔到的大的垃圾桶内,这样就减少了我们直接去大垃圾桶的次数,提高了扔垃圾的效率。这里的小垃圾桶就是一个buffer的实现。
cache
cache中文为缓存,高速缓冲存储器。
a part of a computer’s memory that stores copies of data that is often needed while a program is running. This data can be accessed very quickly.
一般将频繁读的数据放到读取效率更高的存储中,比如内存相比磁盘读取效率更高,比如CPU对应的L1、L2多级缓存之间也有读取速度差异,以此提高读性能,是一种提前读思想的实现,以此提高系统性能。
结合生活中的例子,比如开发与产品同学的工位离得比较远,而做同一个项目时交流过于密切次数过于多,那么我们可以把工位拉近,背靠背工作,这样就减少了大家面对面沟通的成本,提高了沟通协作效率。这里的工位背靠背就是一个cache的实现。
类比
除了buffer与cache,我们以同样的思路可以对比下Linux中的page与swap设计。
page
比如page主要提供了数据读写逻辑单位的机制,比如Linux默认一个页是4KB,当然这个是可配置的,核心解决的问题是:内存有限的情况下,无需加载所有数据到内存中,而是按页逐页加载。
用多少加载多少,并且按页读取也是一种局部性(挨着近使用上应该也是相近的)的设计。
swap
又比如swap区主要是提供了一种磁盘物理中间区域,解决的核心问题是:内存有限的情况下,OS依然可以运行多进程,只不过有些后台进程的数据被切到了swap中,程序读写内存通过swap作为中间层转换。
比如生活中几个人合租房子,合租可以租一个卧室,也可以租两个卧室,按照你的量来进行选择,这就是一个屋子一个page,而整租对于少的人来说就是浪费。而AB两个人同住一个卧室,其中A白天睡,B晚上睡,就是一种swap的设计,谁需要睡觉就把谁的被子拿进来住。
小结
以上我们针对buffer、cache、page、swap几个IO相关的概念做了介绍以及类比。
其中buffer、cache都是缓冲,前者主要是延迟写的思路,而后者主要是提前读的思路。
page、swap,前者解决数据按需读取的问题,后者解决内存有限时运行多进程的问题。