从零实现一个一致性哈希算法,理解+实现。
概念
wiki:
In computer science, consistent hashing is a special kind of hashing technique such that when a hash table is resized, only
n/mkeys need to be remapped on average wherenis the number of keys andmis the number of slots. In contrast, in most traditional hash tables, a change in the number of array slots causes nearly all keys to be remapped because the mapping between the keys and the slots is defined by a modular operation.
一致性哈希,也叫哈希环,是一种对传统哈希表rehash过程的改进算法。通过创建一个环结构,加入虚拟节点,改变寻址逻辑:根据key产生的hashcode在环上寻找下一个虚拟节点,以此提升增删真实节点之后的性能。
场景预设
分布式缓存,我们的集群中有多个节点,数据根据key分区到不同节点。
传统hash路由
假定我们的hash结构现在存储的是 数据key->访问节点 ,那么通过数据key查询时就可以定位到实际存储的节点,也就起到了数据分区、负载均衡的作用。
首先回顾下传统hash函数,也叫散列函数,目的是将指定的入参转换成一个固定的key,如hashCode、MD5、Murmurhash。
而传统hashtable、hashmap的实现下,一旦节点失效,则需要挪动所有的key(因为我们存的是 key->节点),rehash分布,开销巨大。
普通hash:一旦节点发生变动,所有数据均参与到rehash搬运中,开销涉及到所有节点对应数据量。
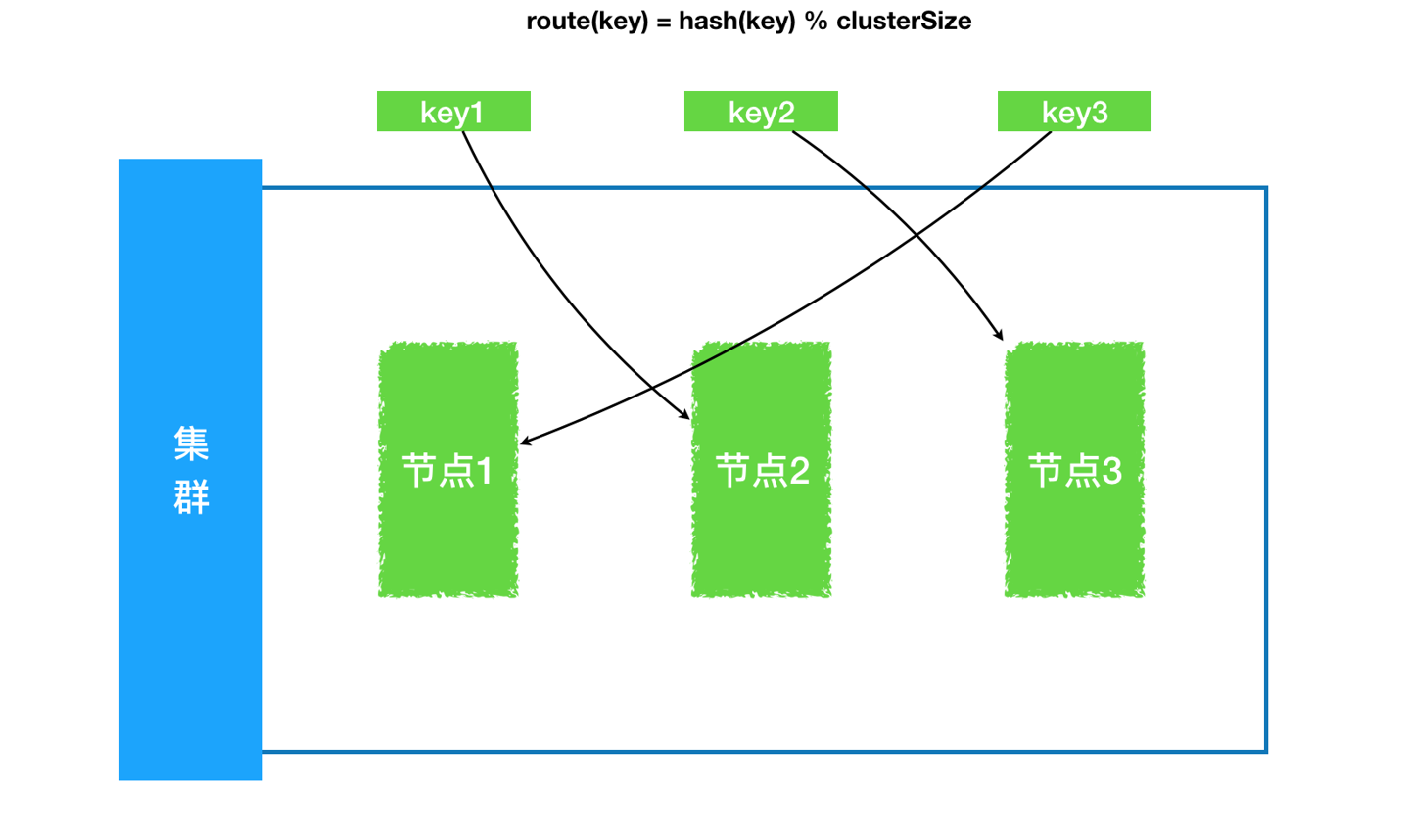
我先实现了一个基于哈希表的coordinator,协调者是分布式常见组件。
参见:HashTableCoordinator 。
一致性哈希路由
而一致性hash,将增删节点后的开销降低到了最低。
一致性hash:某个节点发生变动,仅有该节点数据分摊到其他节点中,开销涉及到单个节点对应数据量。
设计思路
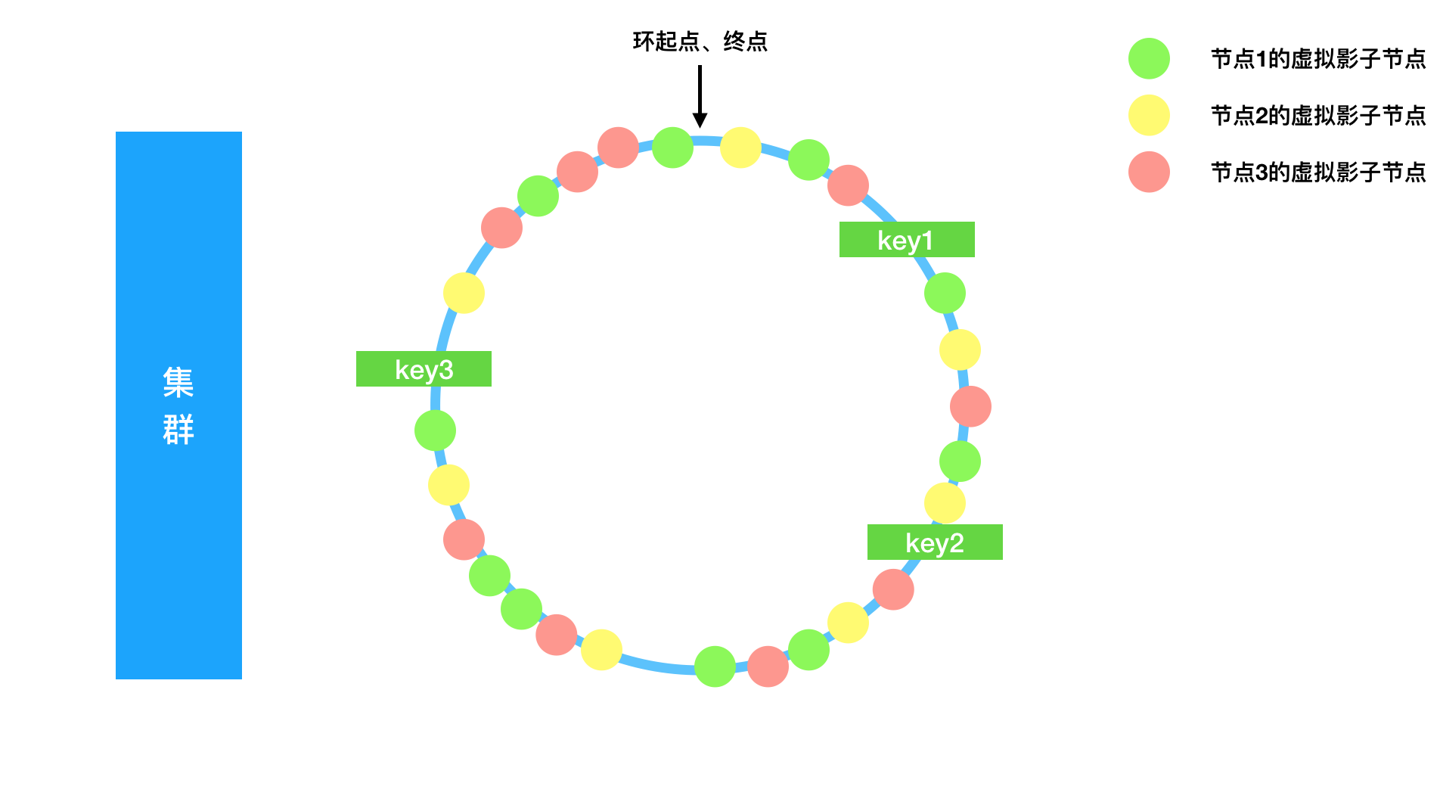
- 使用环状结构存储节点;
- 对应到代码中则是一个有序集合,我们可以考虑红黑树(足够平衡)、跳表,方便快速找到对应值的后续值,同时插入、删除数据复杂度也很低;
- 环上,节点之间增加若干虚拟节点,供映射
虚拟节点->真实节点的关系;- 增加虚拟节点的原因是为了均衡环上数据的分布,因为数据要找节点,而只有真实节点的话,增删一个节点必然导致节点间距不同、分不均;
- 而这里我们加入了足够多的虚拟节点,每个虚拟节点按顺序关联到真实节点上,虚拟节点在环上分布足够均匀;
- 新增节点:创建一个真实节点,同时根据
hash均匀创建环上的若干虚拟节点; - 下线节点:去掉
node,也去掉关联的一批虚拟节点,数据key下次查找时根据环上hashcode顺次查找到另一个虚拟节点上,触发对应据的更新,由于虚拟节点足够多,数据更新被延迟加载,同时分布够均匀;
- 根据
key查找节点的过程:- 根据
key生成hashcode,在环上根据hashcode顺序查找,找到对应虚拟节点,就找到了真实节点;
- 根据
图例
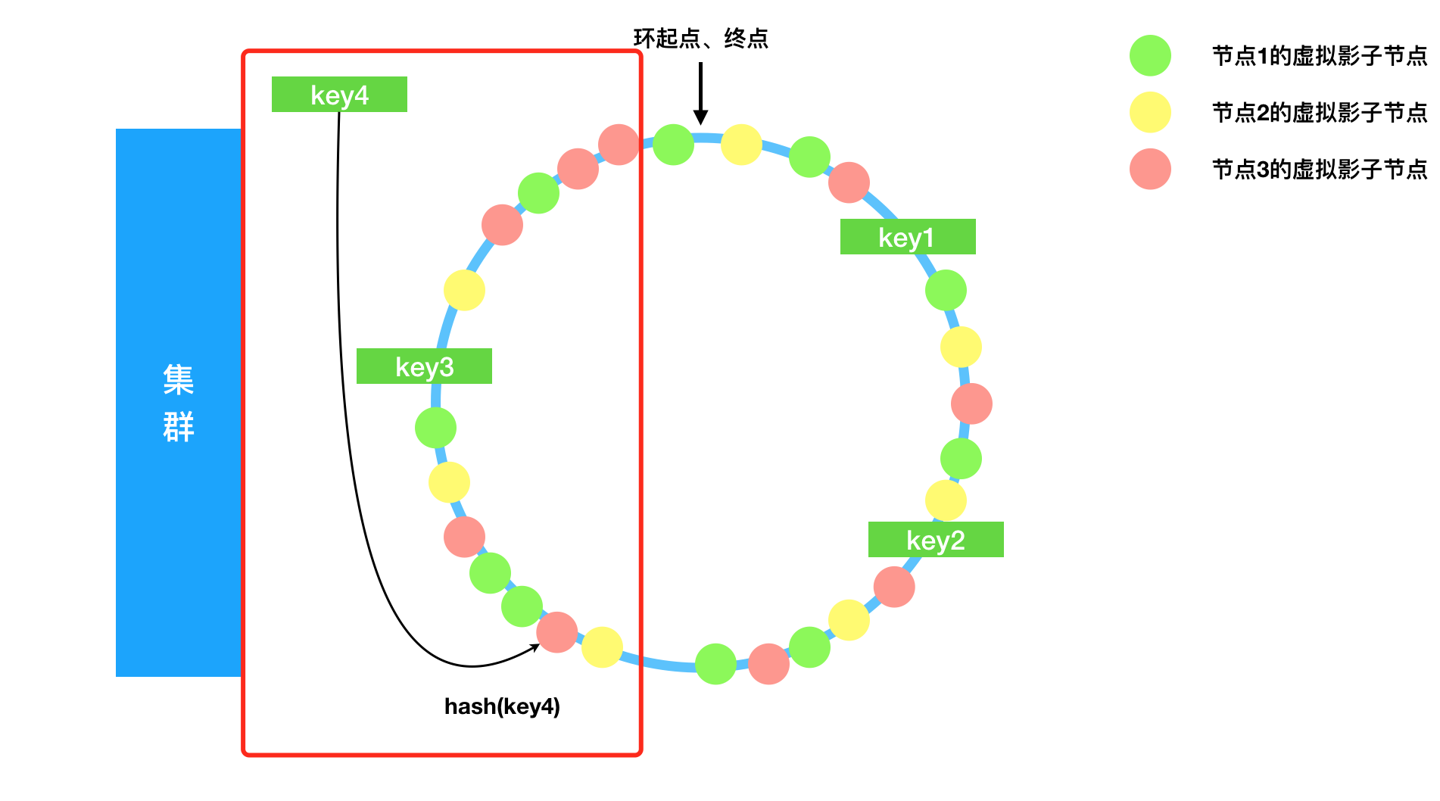
查找
假设此时来了一个key4查找对应数据,那么先经过我们的murmurhash计算出一个long值,对应到环上的一个位置,也就是跳表或者红黑树上的一个点,这个点之后一定有我们预先插入并且足够散列的一个虚拟节点,通过虚拟节点就可以找到真实节点,进而获取数据。
如图:
增加新的节点
假设我们新增了节点4,在数据结构中的体现:
- 新增节点4存储;
- 新增虚拟节点到节点4的映射;
同时我们假设一个节点对应10个虚拟节点节点:
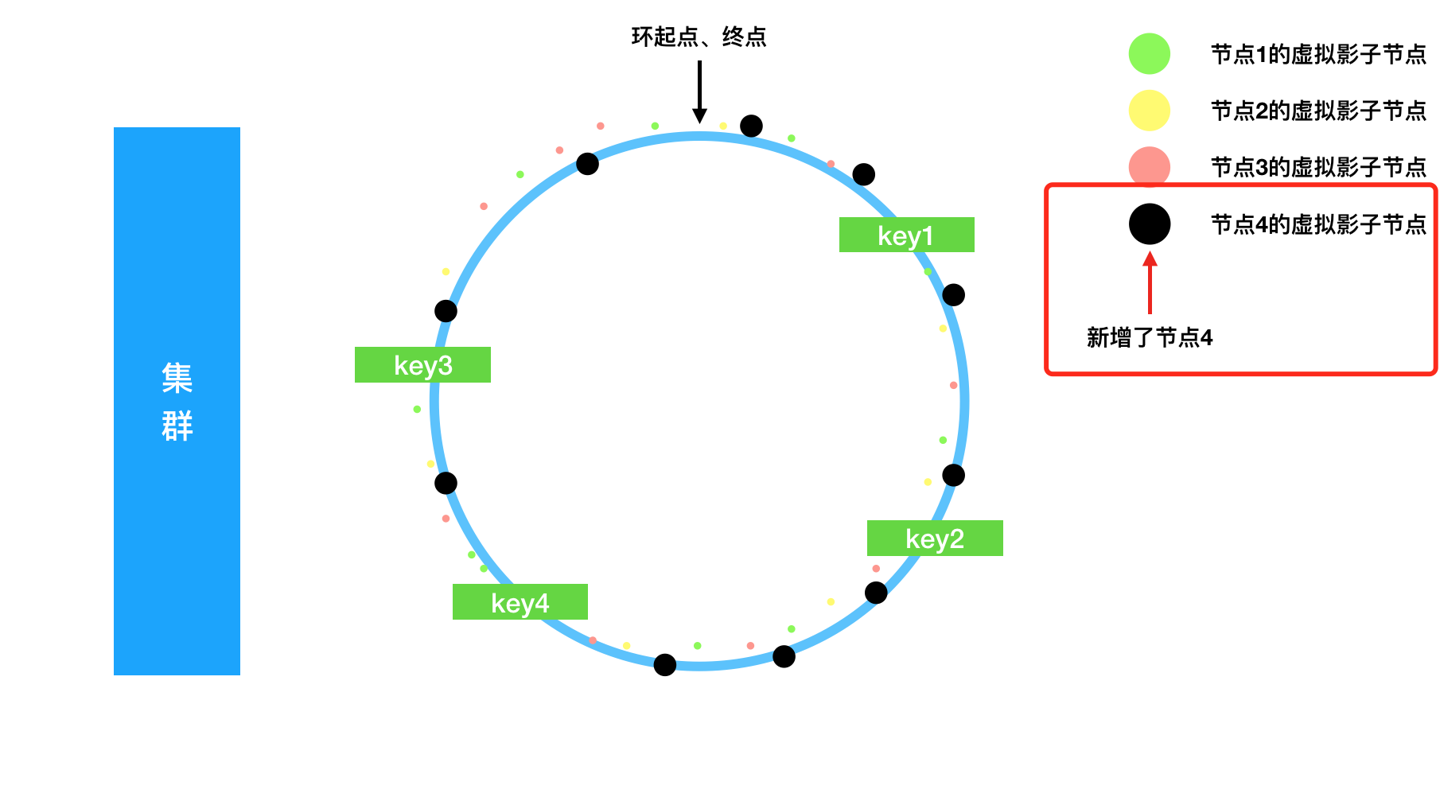
可以看到我们的虚拟节点根据hash尽可能均匀的分布在环的各个位置,在我们的数据key足够多的情况下,会有近似 keyCnt/virtualNodeCnt 个key被归属到了新的虚拟节点,新的真实节点会接管这些key数据。
keyCnt 总数据量 virtualNodeCnt 虚拟节点总量
相比传统哈希表的全量rehash开销控制到了最小。
删除老的节点
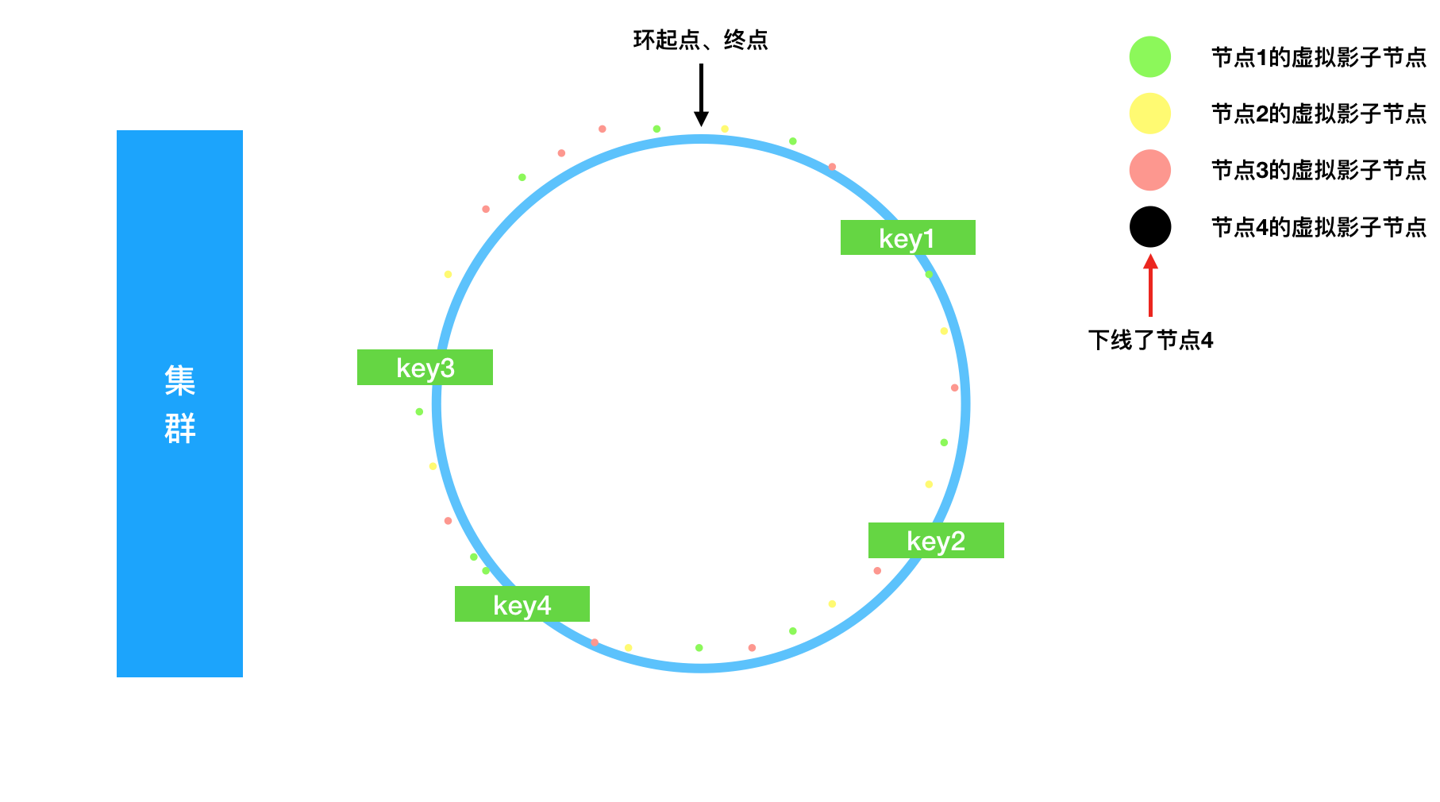
集群碰到老的节点下线是很常见的。
在数据结构中的体现:
- 移除节点4存储;
- 移除虚拟节点到节点4的映射;
此时我们的环图退回到了之前的状态,节点4管理的key根据环依旧可以找到其他节点归属,并且节点4的数据被近似平分到了其他节点上,如图:
实现
单纯看理论总觉得空洞,我们来动手实现一下一致性哈希算法的基本过程。
环结构选型
环的结构要求:
- 顺时针可以找到某个值的下一个值,也就是说数据结构需要有序,并且可以很快找到后续值;
- 添加新数据需要足够高效;
- 移除老数据也需要高效;
JDK中有序的集合大概有:
- 优先级队列
PriorityQueue但是只能比较方便的获取最值 - 红黑树
TreeMap - 跳表
ConcurrentSkipListMap
TreeMap 与 ConcurrentSkipListMap 都可以比较好的满足我们的要求。二者均实现了 SortedMap 接口,可以方便的获取顺序值的前后元素。
本文我们就用 ConcurrentSkipListMap了。
提供的功能
- 初始化环:节点->虚拟节点映射;
- 新增节点;
- 移除节点;
- 根据数据
key获取数据;
代码
|
|
UT测试
- 测试基本流程是否有误;
- 测试节点分布是否均匀;
参见:ConsistentHashCoordinatorTest
根据用例的输出,可以方便的看到读取数据的分布情况:
|
|
达到了期望。
总结
以上,理论分析了一致性哈希的基本过程、关键点,并实现了最基础的一个一致性哈希结构,输出了用例效果。