了解LRU工业级实现,以MySQL、Redis为例。
LRU基本实现及优化 中,我介绍了LRU算法的基本逻辑并给出了实现,本文我们来了解下工业级应用是怎么设计、实现LRU的。
低频访问的数据,如果继续留存在缓存中的话,会浪费缓存空间、内存。这就是缓存污染。
LRU是一种缓存替换、淘汰策略,这种策略核心目的就是尽快淘汰缓存的污染项。
MySQL
版本:5.7
MySQL的Buffer Pool是一块缓冲区域,用内存存储了表、索引信息,加速频繁操作的数据读取。
Buffer Pool结构
借用官方文档的图:
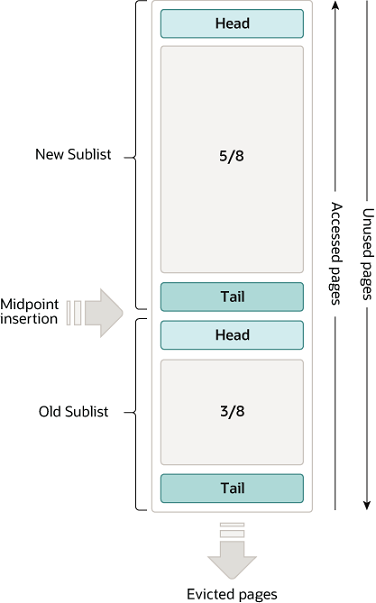
Buffer Pool整体依然是一个链表结构,每一个节点是一个page,一个page中可容纳多行数据(对CPU缓存行更友好)。
相比我们实现的双向链表,MySQL Buffer Pool 链表分成了两大区域:
- New Sublist
New区数据由Old区被频繁访问的数据晋升而来,表示的是读取更多更需要缓存的数据
- Old Sublist
- 新缓存先进入
Old区,如无频繁读取则快速淘汰
- 新缓存先进入
设计剖析
New区Old区,这是典型的分代设计。默认比例:New5Old3。
新老代区分,是为了提高缓存的命中率,淘汰不太需要的数据。
比如有些全量查询会将大量数据丢入Buffer Pool内存,而后续这些数据的读取很少,如果仅用我们之前的实现,这些数据就需要更久的时间被淘汰,也就是缓存的污染程度变高了。
分代之后,读取更多的数据很快晋升到New区,而Old区比例更小,读取不频繁的数据可以更快被淘汰。
Monitoring the Buffer Pool Using the InnoDB Standard Monitor 记录了InnoDB Standard Monitor下Buffer Pool相关的监控指标项,其中有的指标与LRU有关。
小结
InnoDB中的Buffer Pool LRU设计是一种变体,加入了分代的设计,区分了高频、低频访问的数据,能更快地淘汰低频访问的数据,提高了内存的利用率、缓存的命中率。
Redis
版本:4.0
Redis中提供了多种淘汰策略:
- noeviction
- volatile-random
- volatile-ttl
- volatile-lru
- volatile-lfu
- allkeys-lru
- allkeys-random
- allkeys-lfu
其中volatile表示淘汰针对的是设置了过期时间的数据,allkeys针对所有数据。
lru后缀则是本文关注的算法相关项。
Redis通过maxmemory配置服务端的最大内存容量,实际数据超出这个值之后,就开始执行淘汰策略。而volatile类型的key则只要达到过期时间就开始淘汰。
Redis的LRU设计也是另一种变体,是一种近似的算法:Approximated LRU algorithm。
每次淘汰时,对maxmemory-samples 5【配置项】个数据进行采样,选其中最应该淘汰的数据剔除内存。
效果:

设计剖析
Redis源码相对少很多,我们从源码的角度来看看。
redisObject 全局对象
Redis全局对象redisObject定义了一个lru时间戳字段:
|
|
db.c 定义db级别的c api
lookupKey 函数负责从全局哈希表中找到对应的kv。
|
|
可以看到16行会更新lru时间戳。
server.c 定义服务端全局行为
server.c 中的serverCron负责定时任务的执行,注释上可以看到:
- 以
server.hz配置项为周期运行 - 通过定时的方式完成异步任务
- 其中就包括本文涉及的
key淘汰任务的触发,这类任务是一种惰性的查找式设计
- 其中就包括本文涉及的
processCommand 处理请求,其中会检查内存是否达到maxmemory,调用了freeMemoryIfNeeded,以此来触发缓存淘汰流程。
服务端启动时,调用了evictionPoolAlloc,这里会初始化lru淘汰使用的一个池,内部是evictionPoolEntry 结构,主要记录了keyname、idle字段。
freeMemoryIfNeeded 中调用 evictionPoolPopulate 来更新待淘汰的键值数据。
之后直接调用删除内存的实现。
采样筛选的逻辑
|
|
小结
Redis中实现的LRU变体流程:
processCommand处理请求,检查内存是否达到maxmemory,定时任务中也会有触发入口;freeMemoryIfNeeded中检查、计算待释放的内存;evictionPoolPopulate更新淘汰池;- 采样,选择采样样本中最应该淘汰的
bestKey; - 执行淘汰;
核心是近似获取待删除的数据key。
近似的目的是为了节省内存,保证精确的链表结构需要维护在内存中。同时定时定量拉取数据保证了淘汰操作只占用恒定的内存,有利于Redis服务端的稳定运行。
总结
MySQL中主要通过分代来更快淘汰污染的缓存。而Redis主要通过定量拉取、近似采样的方式节省服务端内存,也保证了服务稳定运行。
可以看到工业级实现会有更多的考虑:
- 判断服务端真实使用场景;
- 节省内存;
- 保证服务端稳定;