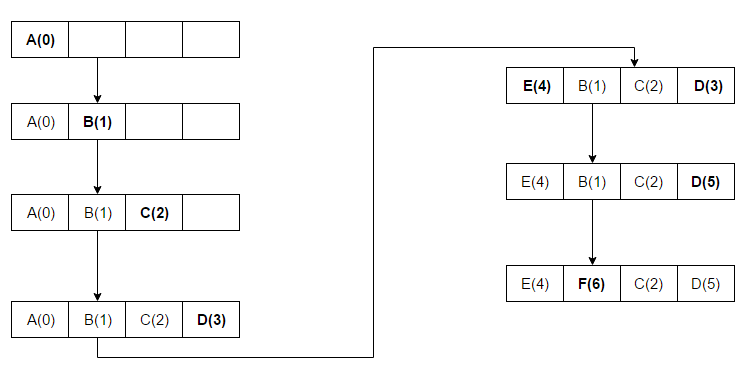
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
|
public class DoubleLinkedListLRU<K, V> {
/**
* first head 指向第一个真实节点的prev
*/
DoubleLinkedListNode<K, V> head;
/**
* last tail 指向最后真实节点的next
*/
DoubleLinkedListNode<K, V> tail;
/**
* 当前数据量
*/
int size;
/**
* lru容量
*/
int capacity;
/**
* 通过key定位链表中的双向链表节点
*/
Map<K, DoubleLinkedListNode<K, V>> k2Node;
public DoubleLinkedListLRU(int capacity) {
this.size = 0;
this.capacity = capacity;
k2Node = new HashMap<>(MapUtils.capacity(capacity));
this.head = new DoubleLinkedListNode<>();
this.tail = new DoubleLinkedListNode<>();
head.next = tail;
tail.prev = head;
}
public V get(K key) {
// O(1)
DoubleLinkedListNode<K, V> node = k2Node.get(key);
if (node == null) {
return null;
}
// O(1)
// 删除原位置元素
removeNode(node);
insertNewHead(node);
return node.entry.val;
}
public void put(K key, V val) {
// O(1)
DoubleLinkedListNode<K, V> targetNode = k2Node.get(key);
if (targetNode == null) {
// 数据原来不存在
if (size == capacity) {
// 淘汰末尾元素
evictTail();
}
DoubleLinkedListNode<K, V> newNode = new DoubleLinkedListNode<>(key, val);
insertNewHead(newNode);
++size;
} else {
// 数据原来已存在,直接更换节点位置
removeNode(targetNode);
insertNewHead(targetNode);
}
}
// O(1)
private void evictTail() {
DoubleLinkedListNode<K, V> last = tail.prev;
tail.prev = last.prev;
last.prev.next = tail;
last.next = null;
last.prev = null;
k2Node.remove(last.entry.key);
--size;
}
// O(1)
private void insertNewHead(DoubleLinkedListNode<K, V> targetNode) {
if (head.next == tail) {
tail.prev = targetNode;
}
targetNode.next = head.next;
targetNode.prev = head;
head.next.prev = targetNode;
head.next = targetNode;
k2Node.put(targetNode.entry.key, targetNode);
}
// O(1)
private void removeNode(DoubleLinkedListNode<K, V> targetNode) {
targetNode.prev.next = targetNode.next;
targetNode.next.prev = targetNode.prev;
k2Node.remove(targetNode.entry.key);
}
public DoubleLinkedListNode<K, V> randomNode() {
int i = NumberUtils.randomInt(size);
System.out.println("randomI:" + i);
DoubleLinkedListNode<K, V> curr = head;
while (i > 0) {
curr = curr.next;
--i;
}
return curr;
}
public void print() {
System.out.println(this);
DoubleLinkedListNode<K, V> curr = head;
while (curr != null) {
if (curr.entry != null) {
System.out.print(curr.entry.val + "-->");
}
curr = curr.next;
}
System.out.println();
}
@Override
public String toString() {
return "DoubleLinkedListLRU{" + ", size=" + size + ", capacity=" + capacity + '}';
}
static class DoubleLinkedListNode<K, V> {
DoubleLinkedListNode<K, V> prev;
DoubleLinkedListNode<K, V> next;
Entry<K, V> entry;
public DoubleLinkedListNode(K key, V val) {
this.entry = new Entry<>(key, val);
}
public DoubleLinkedListNode() {
}
@Override
public String toString() {
return "DoubleLinkedListNode{" + "prev=" + (prev == null ? "null" : prev.entry) + ", next=" + (next == null ? "null" : next.entry) + ", entry=" + entry + '}';
}
}
static class Entry<K, V> {
K key;
V val;
public Entry(K key, V val) {
this.key = key;
this.val = val;
}
@Override
public String toString() {
return "Entry{" + "key=" + key + ", val=" + val + '}';
}
}
}
|