翻译 Alex Xu 的技术 Twitter。Alex Xu 是 System Design Interview 的作者之一。
System Design Interview 中包含了大多数互联网技术体系中常见的系统设计案例,除了书籍,Alex Xu 在他的Twitter上也发了很多技术帖。
本文结构:
- 以场景-方案为单位;
- 说明背景、问题点;
- 阐述方案关键点、解析过程;
词汇:
- reconciliation 对账
- ledger 收支总账、分类账簿
- cut-off 截止点、界限
- discrepancy 差异、不符
- exponential 指数的、(增长)越来越快的
- backoff 补偿
- floating-gate 浮栅
- transistor 晶体管
通用原则
- 针对面试场景,需要聚焦于核心设计,因为面试有时间限制,不可能考虑到实际场景中所有细节;
- 问清晰的问题,表达、阐述清晰;
- 不要过早优化;
CDC变更数据捕获是如何工作的?
https://twitter.com/alexxubyte/status/1527318907786186753
背景
存在某个数据库中的数据对于别的业务节点很有可能是有意义的,比如报表、AI等下游服务,那么每个下游节点都需要定制一套数据格式转换的逻辑吗?
CDC ChangeDataCapture变更数据捕获帮我们解决了这个问题。
变更数据捕获的运行机制
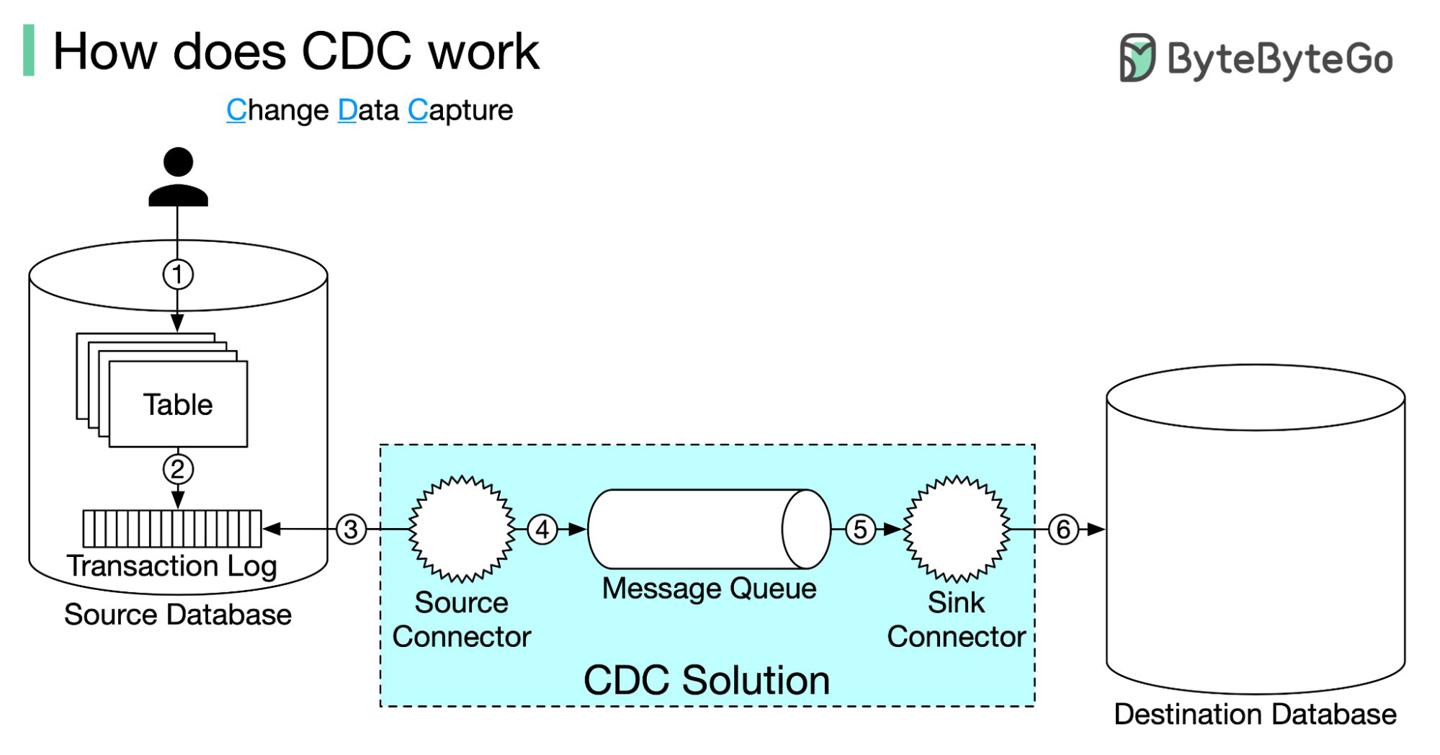
- 数据正常写入数据库;
- 数据库使用事务日志记录变更;
CDC使用source connector连接数据库,读取事务日志;source connector将事务日志作为消息发送到MQ;CDC使用sink connector消费日志;sink connector将日志内容写入到下游;- 除了第三步其他步骤对于用户都是透明的;
主流的CDC实现如Debezium支持了大多数RDBMS:MySQL, PostgreSQL, DB2, Oracle。
开发者唯一要做的就是配置CDC的source、sink。
什么是数据库隔离级别?
https://twitter.com/alexxubyte/status/1526234911178272768
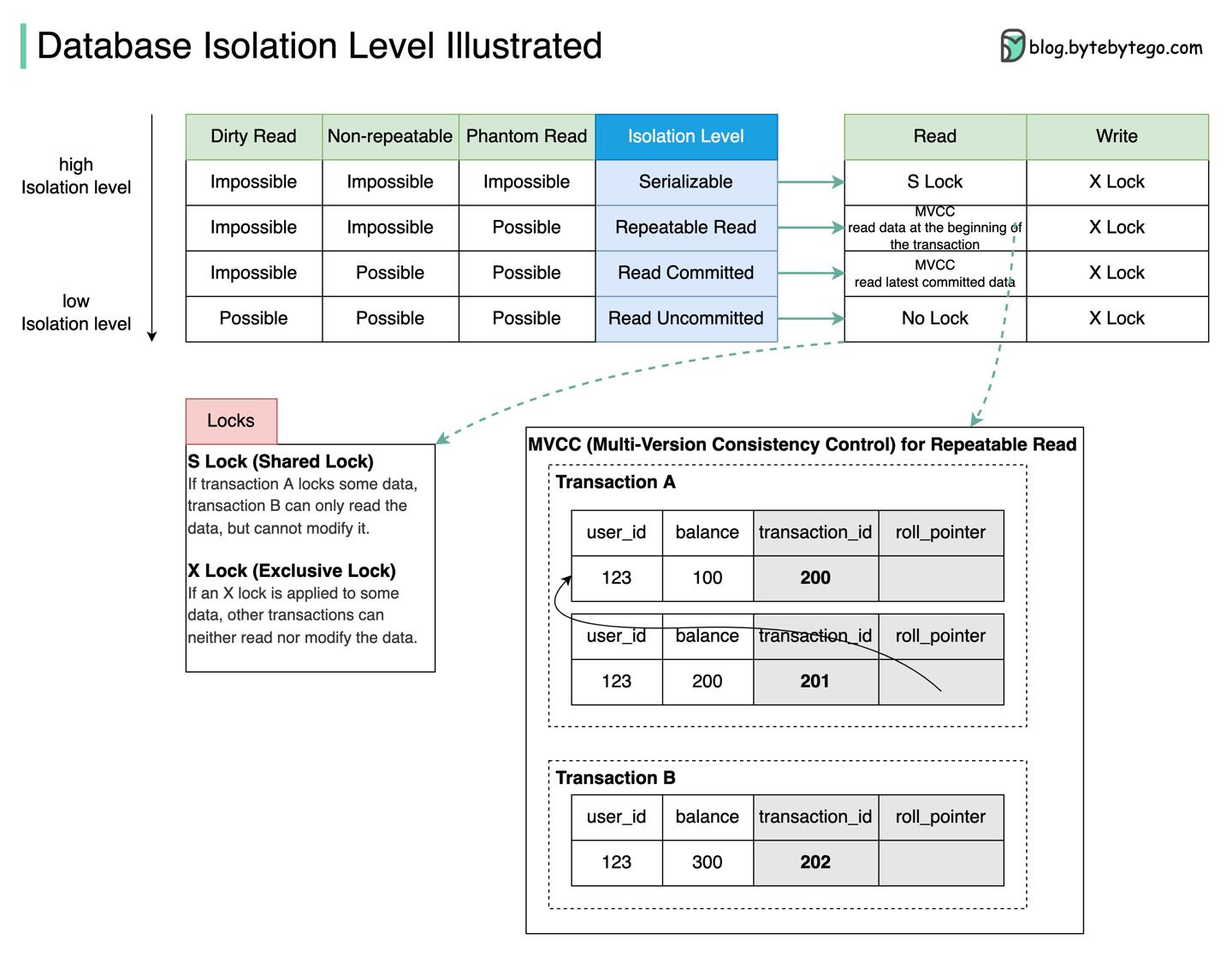
- Serializalble:最高、最严格的隔离级别,并发事务顺次执行;
- Repeatable Read:事务中多次读效果与首次读一致;
- Read Committed:数据变更只能在事务提交后被读到;
- Read Uncommitted:最弱级别,事务提交前的数据可被别的事务读到;
上图中以 Repeatable Read 为例讲解 MVCC 的原理:
- 每行数据有两个隐藏列:
- transaction_id 记录操作的事务id
- roll_pointer 指向事务开启时已提交最新的数据
- 事务A开启:生成
transaction_id=201的快照ReadView; - 事务B开启:生成
transaction_id=202的快照ReadView; - 事务A将余额更新为200,新数据日志落库,
ReadViewroll_pointer 指向旧的数据行; - 在事务A提交前,事务B读取余额,发现事务201暂未提交,根据 roll_pointer 找到当前已提交最新的数据
transaction_id=200; - 此时事务A提交;
- 事务B再次读取余额,
transaction_id=202的快照ReadViewroll_pointer 仍然指向数据transaction_id=200;
什么是SSO单点登录?
https://twitter.com/alexxubyte/status/1523691173327507456
SSO Single Sign-On
背景
用户维护多个网站的用户名、密码多少是个繁琐的事,一旦忘记了某个网站的密码,可能还得回答很多找回密码的认证问题。
单点登录作为一种认证方案,帮我们解决了这个问题:用户使用一个统一的id来访问多个系统。
过程解析
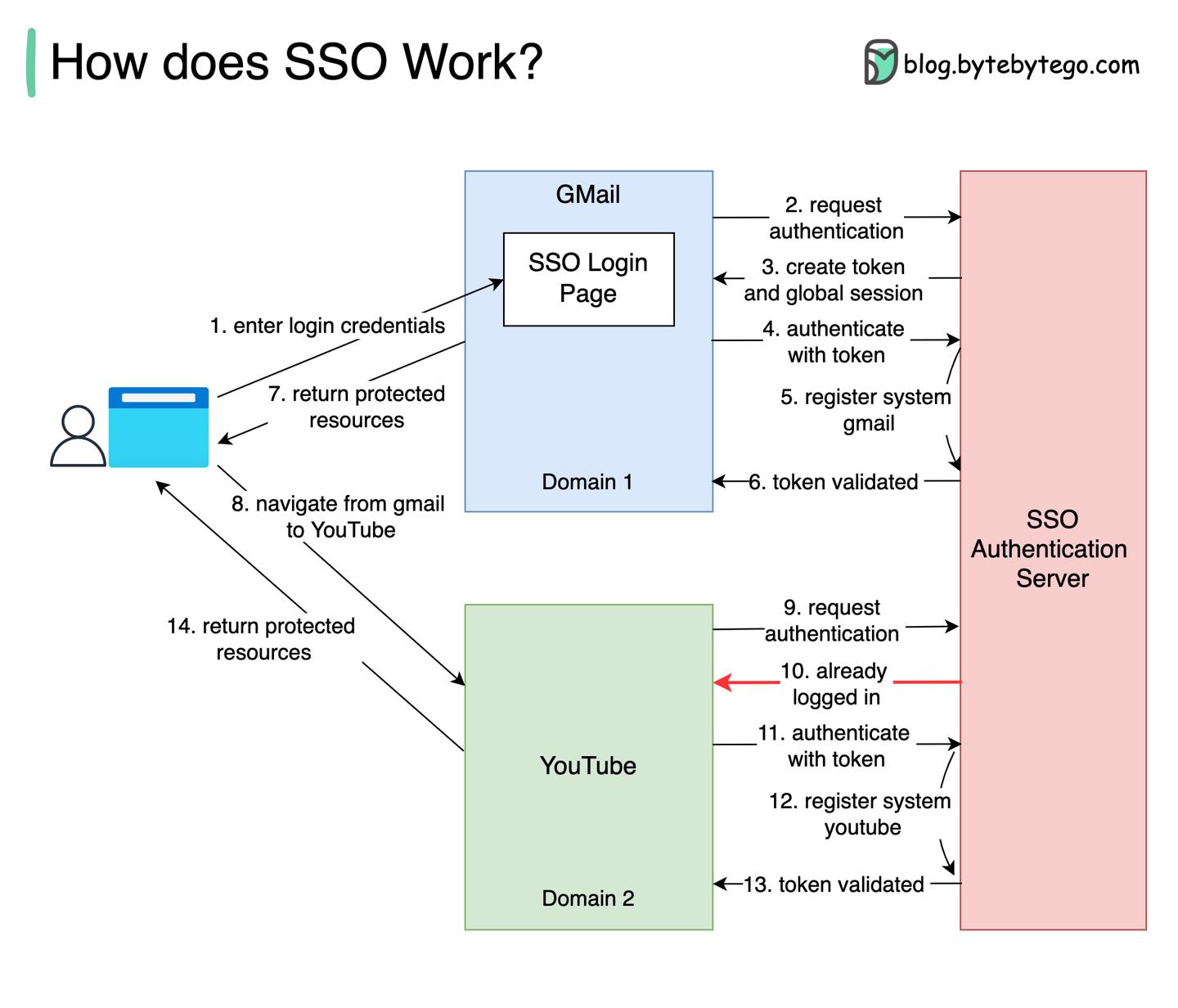
- 用户首先访问
Gmail,此时未登录,用户被重定向到SSO服务端,SSO也认定用户未登录;用户再重定向到登录页,输入SSO认证信息; - 开始请求认证;
- 为用户创建
token、全局session; -
-
-
Gmail携带token去SSO服务端认证,同时注册Gmail状态,返回valid,Gmail给用户返回登录可查看的资源;- 用户此时从
Gmail跳转到另一家Google系的网站Youtube; -
Youtube发现用户未登录,请求SSO系统,发现用户已登录,返回上一步已创建好的token;-
-
-
Youtube携带token去SSO服务端认证,同时注册Youtube状态,返回valid,Youtube给用户返回登录可查看的资源;
如何在数据库安全地存储密码?
https://twitter.com/alexxubyte/status/1522242694004674560
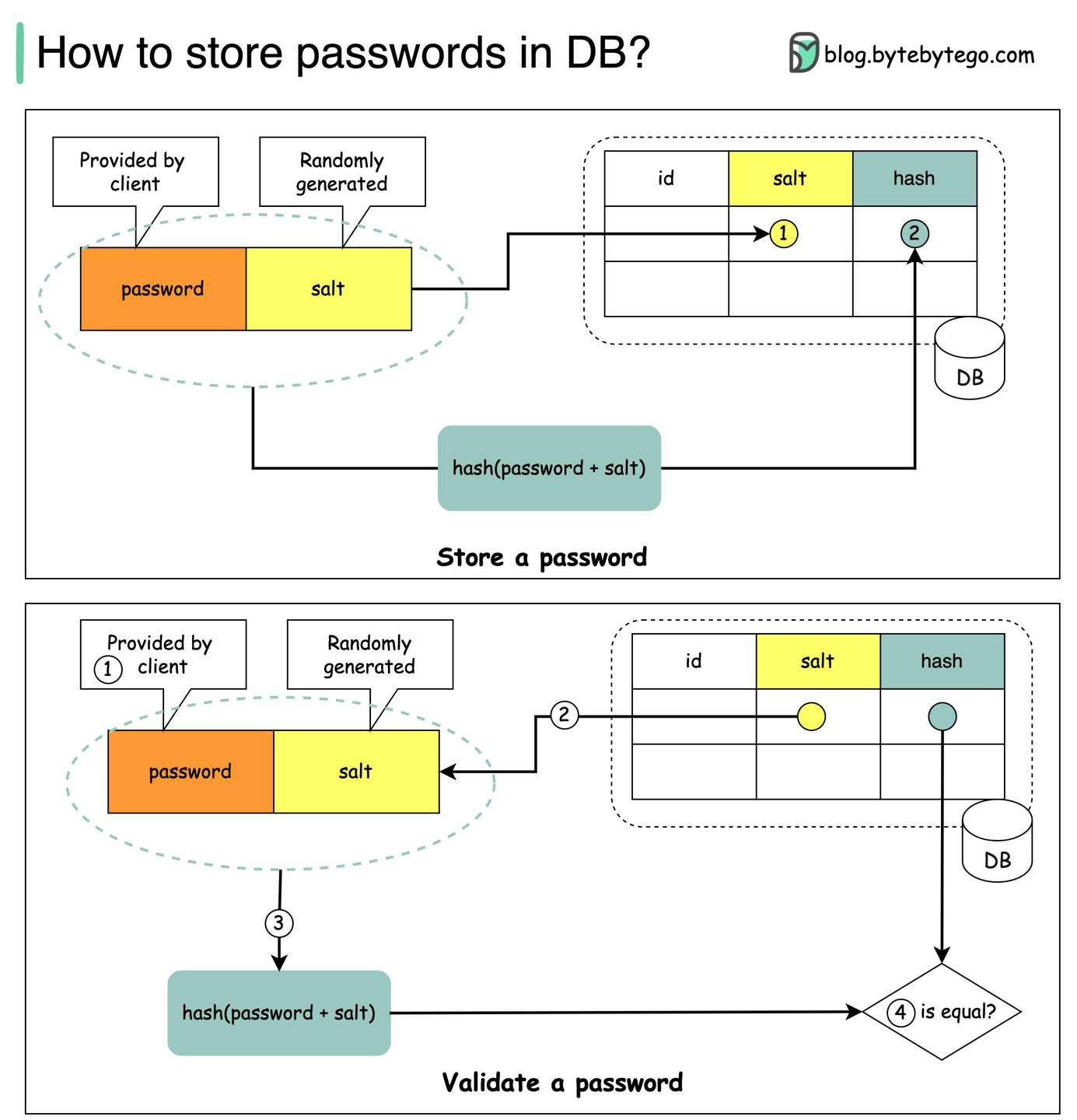
禁止 🈲
- 不要在数据库存密码明文,那样的话内部人员都能看到密码!
- 不要简单对密码
hash后存储,那样的话易受彩虹表(提前把明文hash值缓存,撞库用)攻击!
方案 👌🏻
加盐即可!
盐值不要求是加密的,可以是我们指定的一段字符串(可以考虑存到数据库,后续能拿到即可),用于后续hash匹配唯一性。
hash加盐格式:𝘩𝘢𝘴𝘩( 𝘱𝘢𝘴𝘴𝘸𝘰𝘳𝘥 + 𝘴𝘢𝘭𝘵)。
验证过程:
- 服务端接受到用户输入的密码;
- 获取提前指定的盐值,计算加盐hash值:
𝘩𝘢𝘴𝘩( 𝘱𝘢𝘴𝘴𝘸𝘰𝘳𝘥 + 𝘴𝘢𝘭𝘵); - 对比提前存下的hash值,匹配即为有效;
HTTPS是如何工作的?
https://twitter.com/alexxubyte/status/1521883407864590337
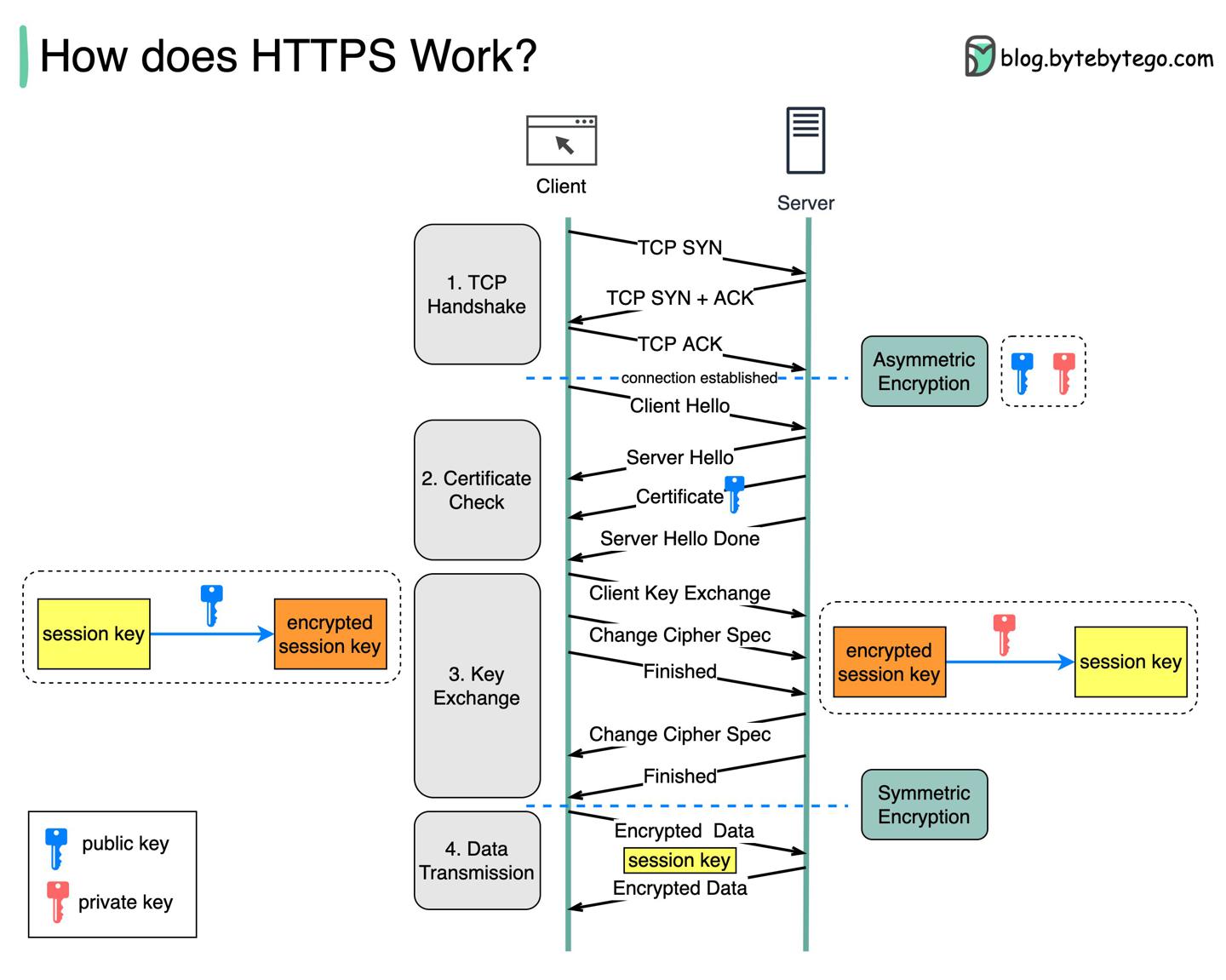
HTTPS:
HTTP安全版的拓展。- 使用
TLS(Transport Layer Security)传输数据。 - 如果消息被拦截,拦截者只能拿到加密的二进制码。
工作流程
- 客户端与服务端先建立一个
TCP连接; - 客户端发送一个「hello」消息给服务端,消息内包含了一组加密算法+最新支持的
TLS版本;- 服务端发回响应,告诉客户端算法与
TLS版本的支持情况; - 服务端接着发送
SSL证书,包含:- 公钥;
- 主机名;
- 过期时间;
- 客户端校验证书有效性;
- 服务端发回响应,告诉客户端算法与
- 证书校验后,客户端生成一个
session key并使用公钥加密,服务端收到后使用私钥解密; - 目前服务端+客户端均持有了同一个
session key(对称加密),加密数据此时双向传输具备了安全性;
HTTPS数据传输使用对称加密的原因:
- 安全性。 非对称加密仅单向生效,也就是说服务端把加密消息返回给客户端后,任意客户端都可以用公钥解密;
- 节省服务端资源。 非对称加密有较多数学计算的开销,这一点不适用于长回话的场景;
如何设计缓存策略?
https://twitter.com/alexxubyte/status/1499428315429412864
Linux性能剖析工具
https://twitter.com/alexxubyte/status/1500881250201976832
排查系统问题时,观察系统层面的很多指标非常常见,可以借助下面的工具。
常用工具
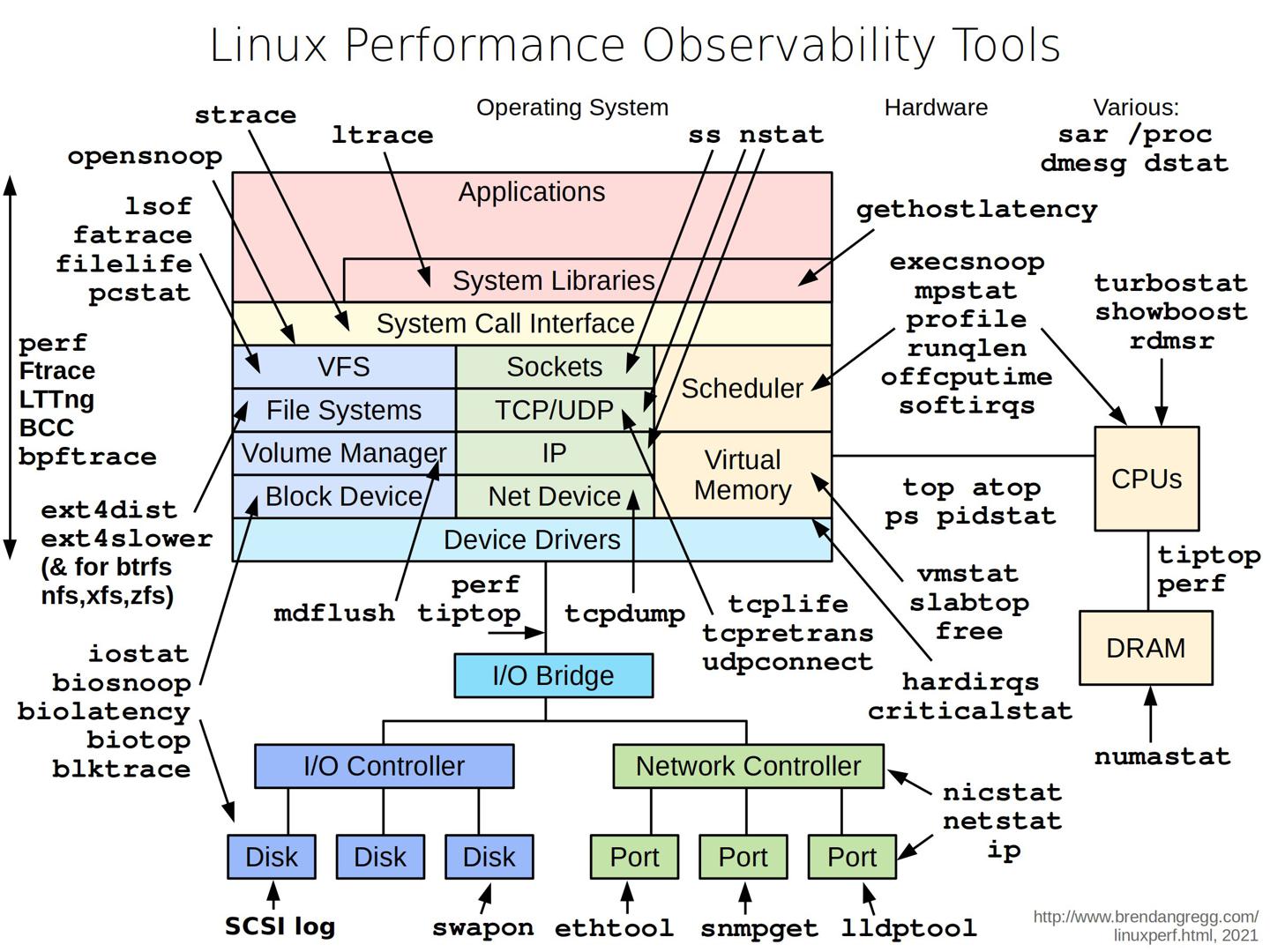
| 命令 | 作用 |
|---|---|
| vmstat | 输出进程、内存、页、block IO、CPU活动信息; |
| iostat | 输出CPU、IO统计数据; |
| netstat | 输出网络统计数据,包括不限于:IP/TCP/UDP/ICMP等协议; |
| lsof | 列出当前系统打开的文件; |
| pidstat | 监控指定或全部进程对应系统资源的使用情况,资源包括CPU/内存/IO/任务切换/线程等; |
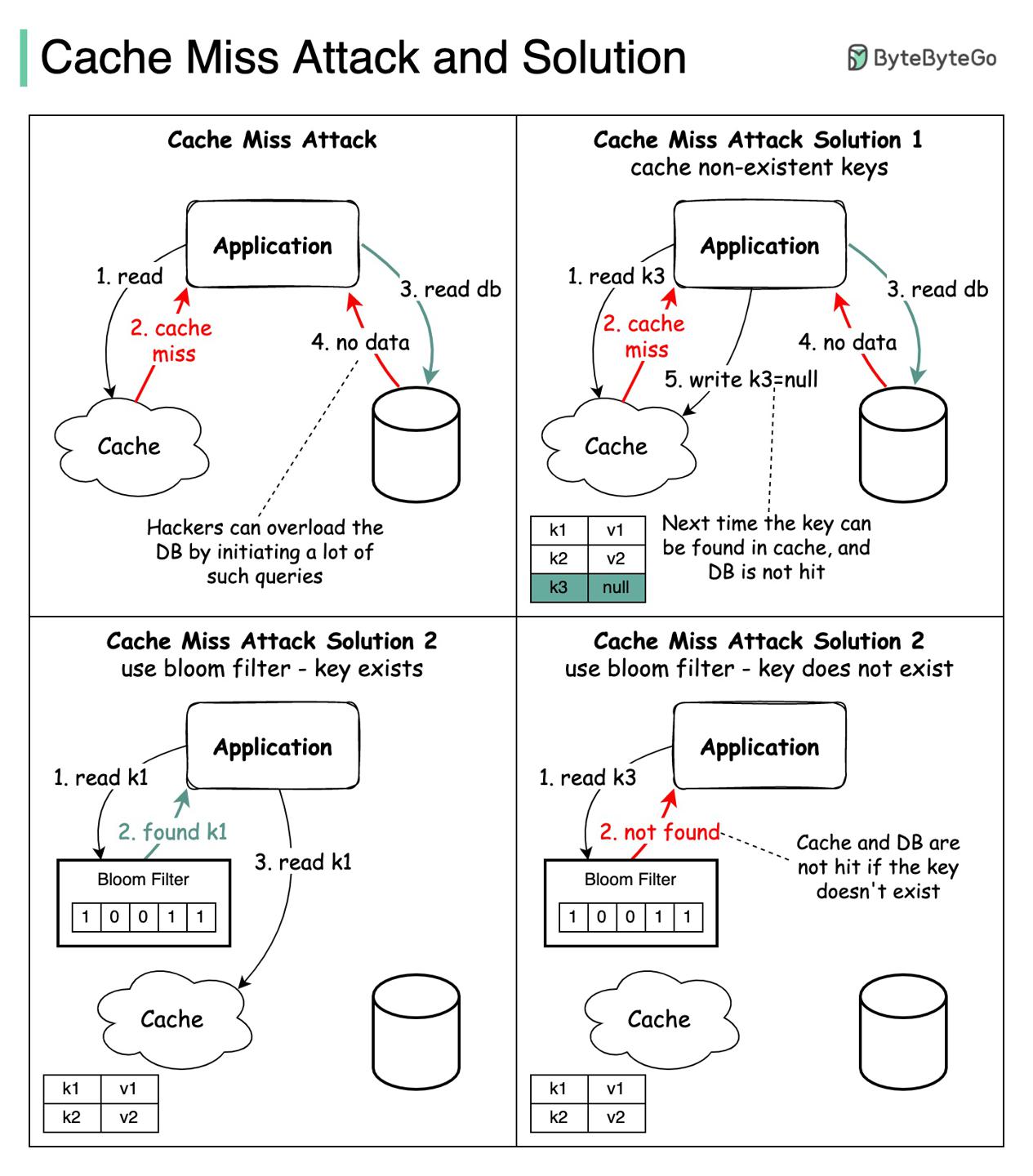
如何避免cache miss attack?
https://twitter.com/alexxubyte/status/1501609063129387014
问题定义
cache miss attack 指的是请求尝试获取数据库与缓存均不存在的数据。
会对数据库带来不必要的负载。有时候这是一种攻击手段。
解决方案
两种通用方案:
- 将
key对应值设为null,同时将值为null的kv设定一个ttl存活时间(节省内存)。 - 使用bloomFilter。
key存在,先查缓存,没有再查数据库;key不存在,fail-fast请求直接返回;
权衡延迟、一致性
https://twitter.com/alexxubyte/status/1502321128752107526
延迟与一致性是相悖的,需要根据实际场景做权衡。

Redis vs Memcached
https://twitter.com/alexxubyte/status/1503401413107347456
对比也可参考:memcached-vs-redis-whats-the-difference
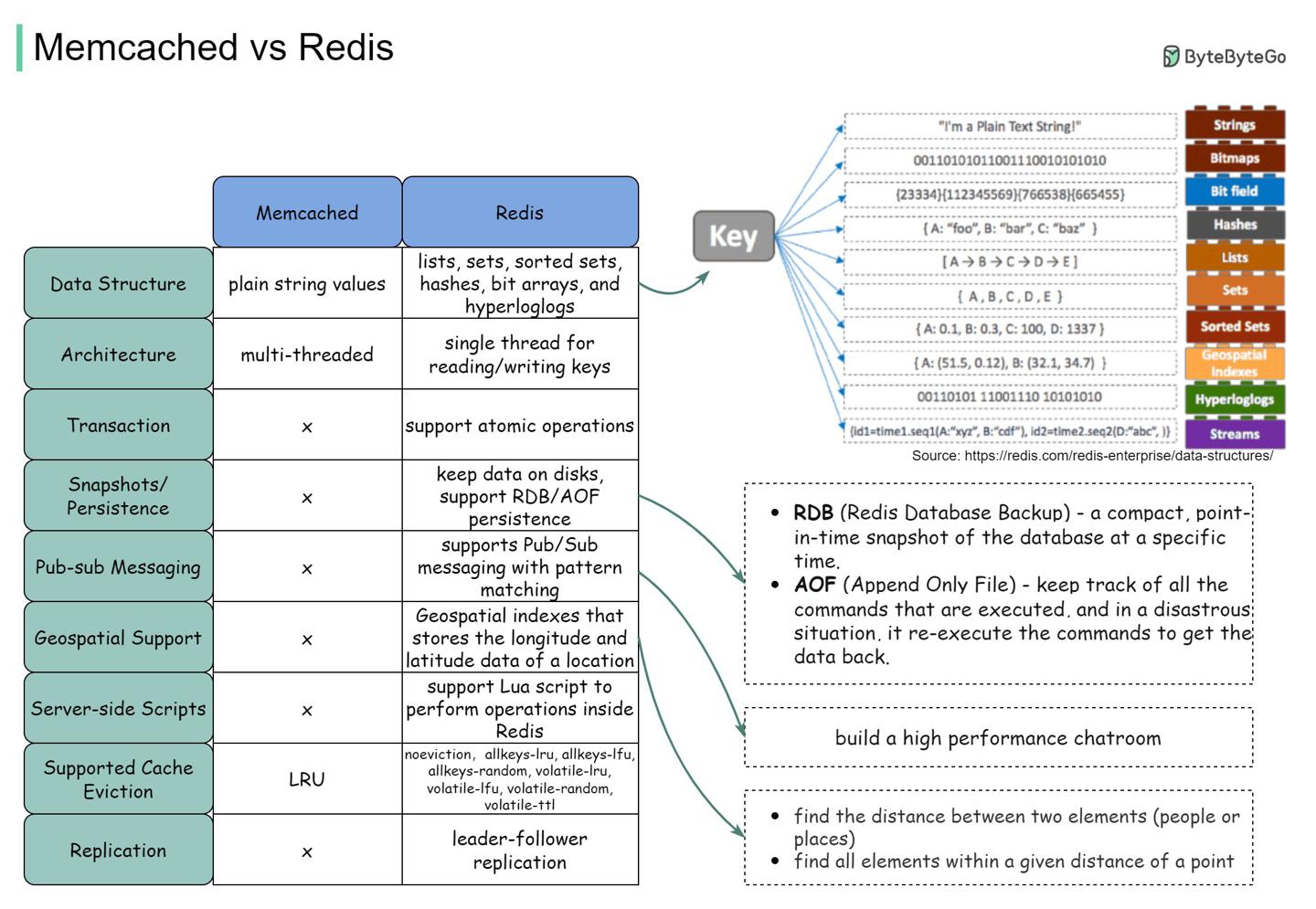
Redis丰富的数据结构有如下优势:
| 数据结构 | 场景 |
|---|---|
| hash | 方便记录每篇推文每次点击、评论; |
| zset | 去重用户数据;排序评论过的用户列表; |
| zset、hash | 缓存用户行为历史;过滤恶意行为数据; |
| bitmap | 使用极小的空间存储非常大量的二值数据,如登录状态、会员状态; |
交互协议对比 SOAP vs REST vs GraphQL vs RPC.
https://twitter.com/alexxubyte/status/1506298328878780419
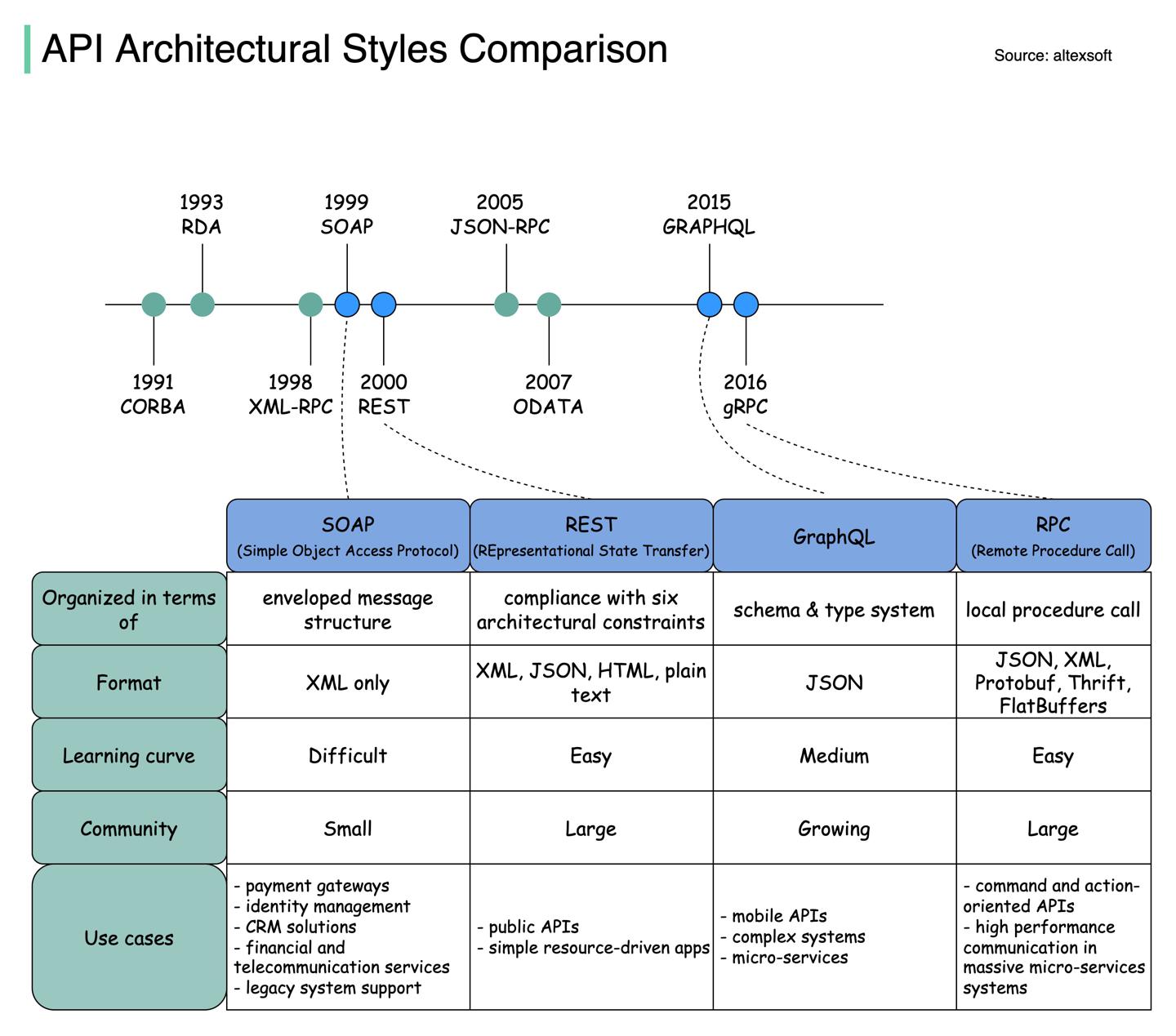
Kafka为什么这么快?
https://twitter.com/alexxubyte/status/1506663791961919488 总结Kafka提升效率的设计要点。
- 顺序IO
- 零拷贝
过程解析
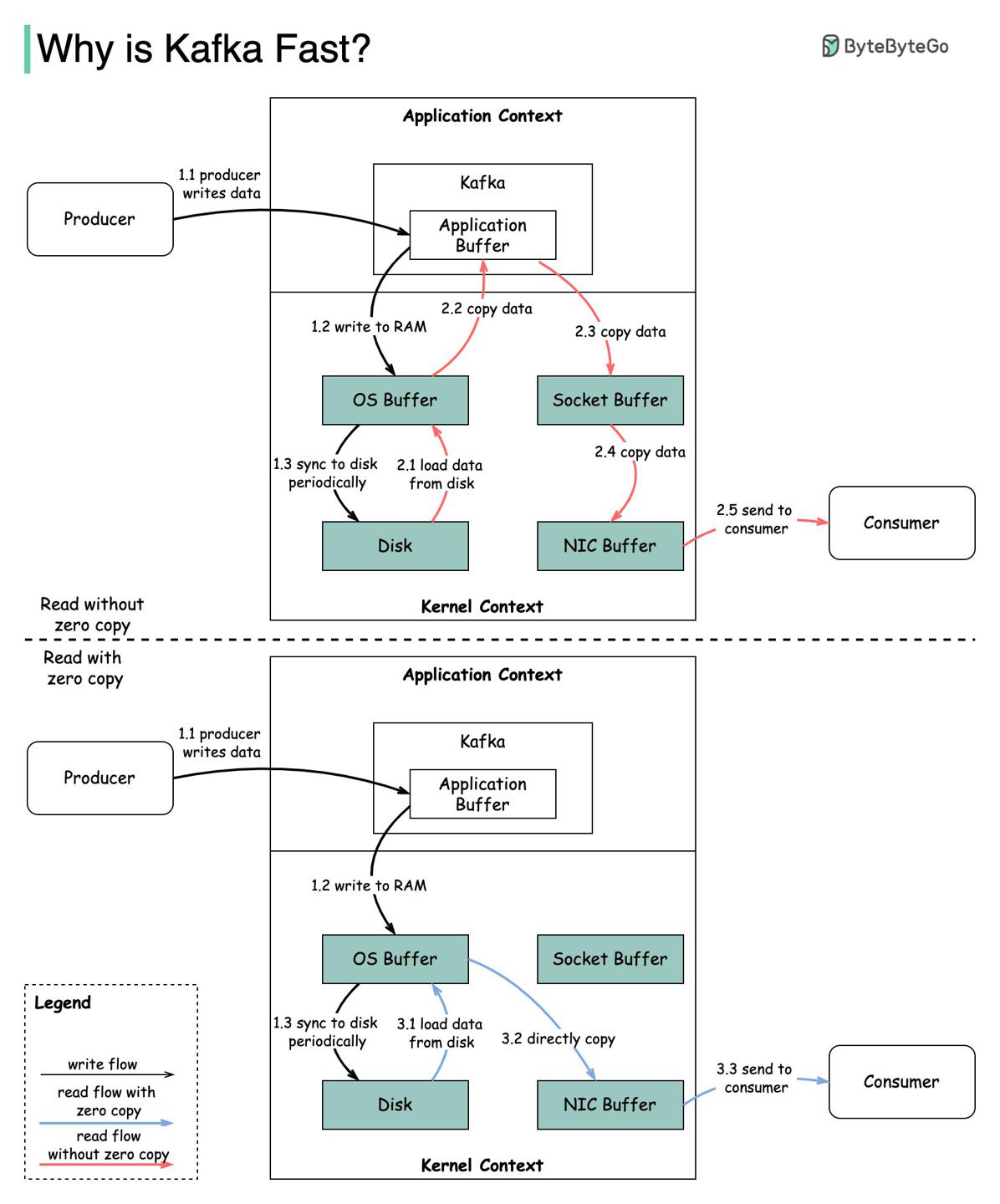
零拷贝
- 步骤1.1-1.3,生产者Producer写入数据到磁盘;
- 步骤二,Consumer不用零拷贝读取数据:
- 2.1 数据从磁盘加载到系统缓存;
- 2.2 数据从系统缓存拷贝到Kafka应用层buffer;
- 2.3 数据从Kafka应用层buffer拷贝到
socket buffer; - 2.4 数据从
socket buffer拷贝到网卡; - 2.5 网卡发送数据给Consumer;
- 相比,Consumer用零拷贝读取数据:
- 3.1 数据从磁盘加载到系统缓存;
- 3.2 系统缓存直接将数据拷贝到网卡
sendfile(); - 3.3 网卡发送数据给Consumer;
零拷贝在数据不做多余处理只是复制传输的场景下减少了拷贝次数(内核、应用上下文),耗时可减少65%。
SaaS vs PaaS vs IaaS vs DDD
https://twitter.com/alexxubyte/status/1507026453572902912
SaaS vs PaaS vs IaaS vs DDD 均为通用的云计算架构,本节简要描述定义、适用场景、发展历程。
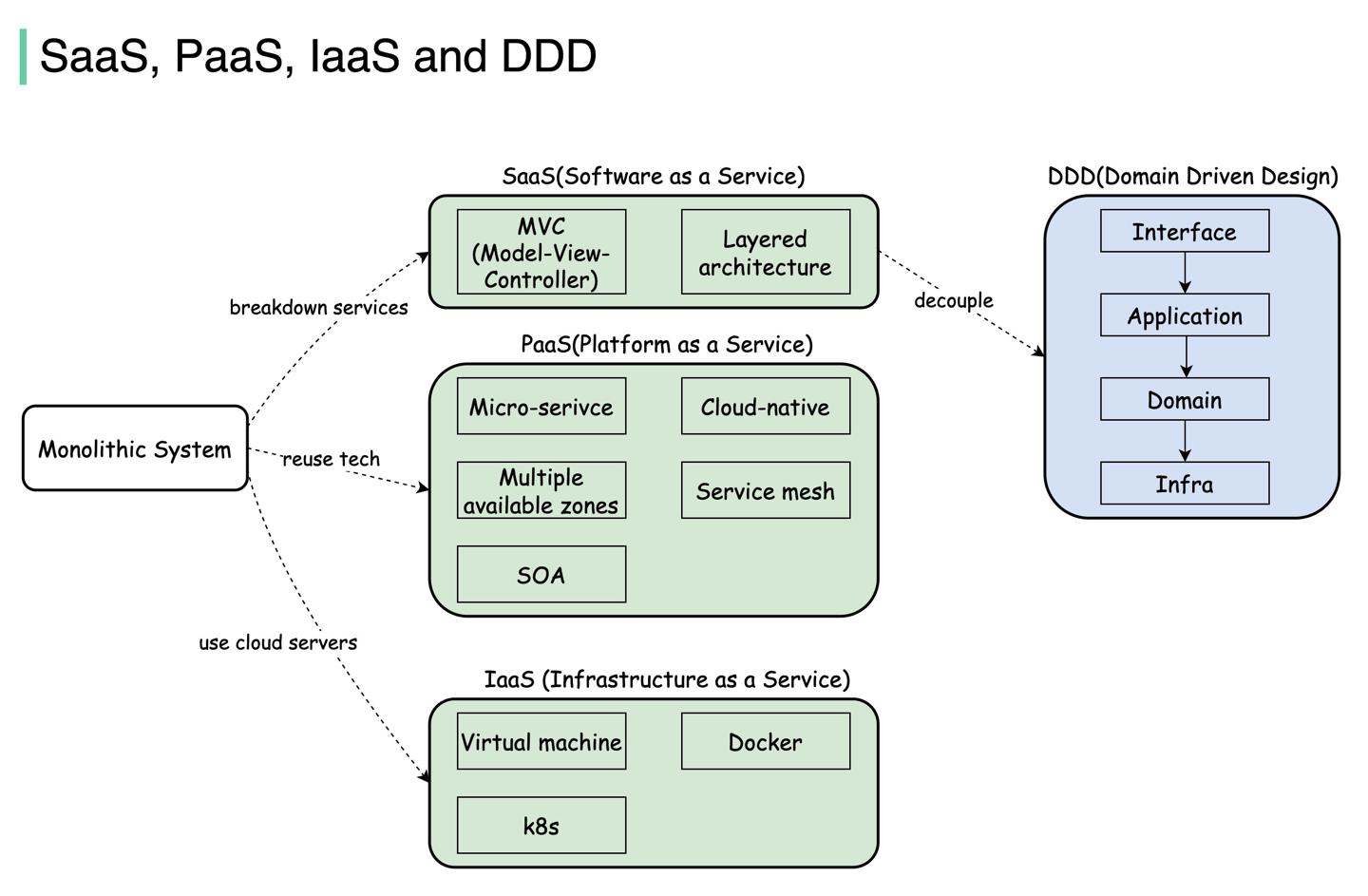
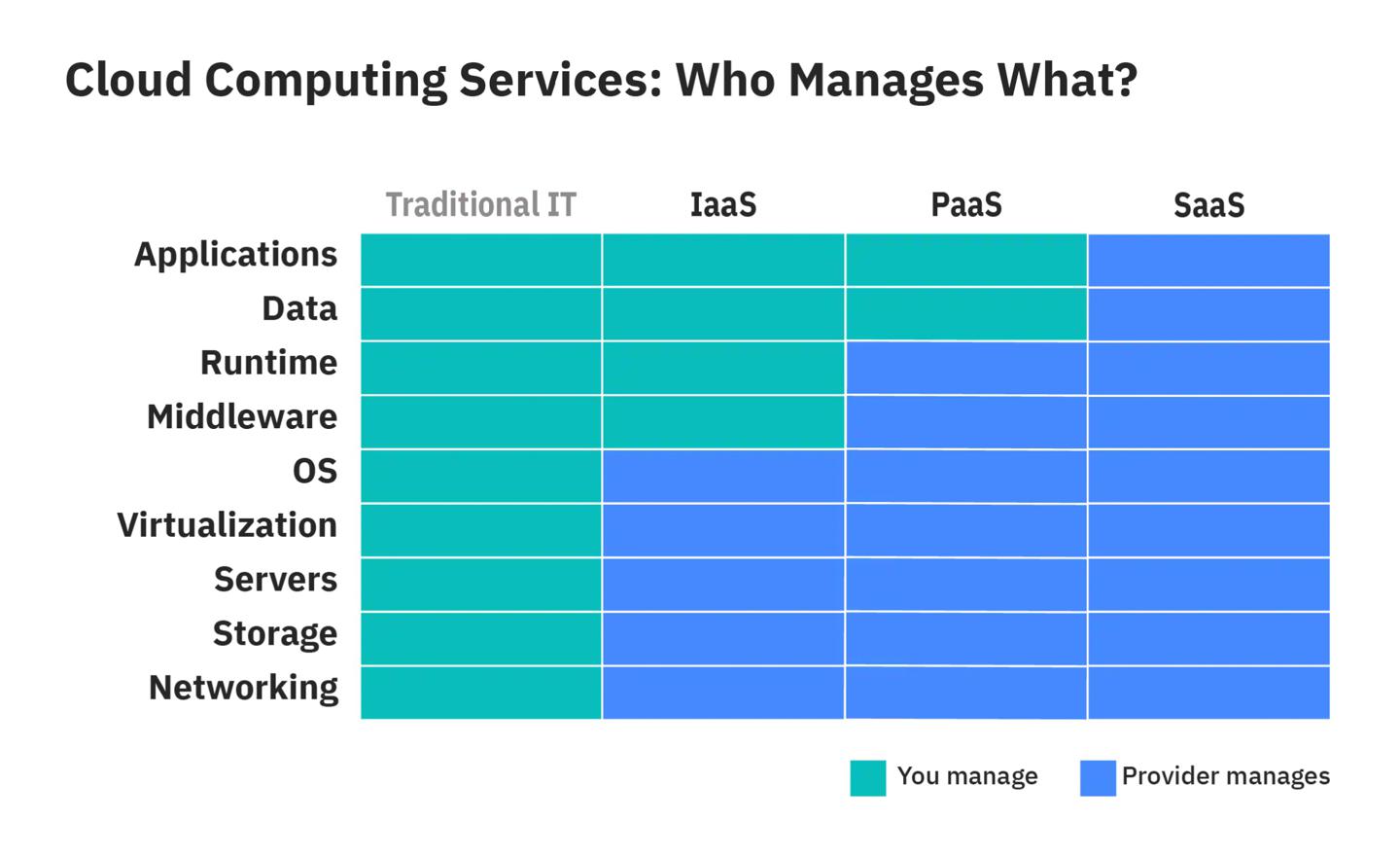
SaaS
SaaS:软件即服务。服务供应商提供云应用,开箱即用。
架构要点:分层,易于拓展、迭代。
PaaS
PaaS:平台即服务。提供基于云的开发、运行、管理应用的平台。
如 AWS Elastic Beanstalk, Google App Engine
架构要点:技术栈复用。抽象公用技术组件、平台。
IaaS
IaaS:基础设施服务。允许多个团队在云平台管理自己的服务器、存储。
AWS, Azure, Google cloud
架构要点:云平台通过虚拟化技术封装了操作系统,方便业务水平拓展业务服务器。
DDD
DDD:领域驱动设计。聚焦于领域建模,匹配领域专家的业务知识。
架构要点:代码复杂度攀升,清晰定义领域边界有利于解耦领域业务。
拓展服务应对量级
https://twitter.com/alexxubyte/status/1508835814469296131
背景
电商网站背景下,用户量激增,服务如何拆分?
假设我们有以下业务系统:
- 库存
- 处理商品、库存
- 用户
- 处理用户元信息、注册登录逻辑
方案
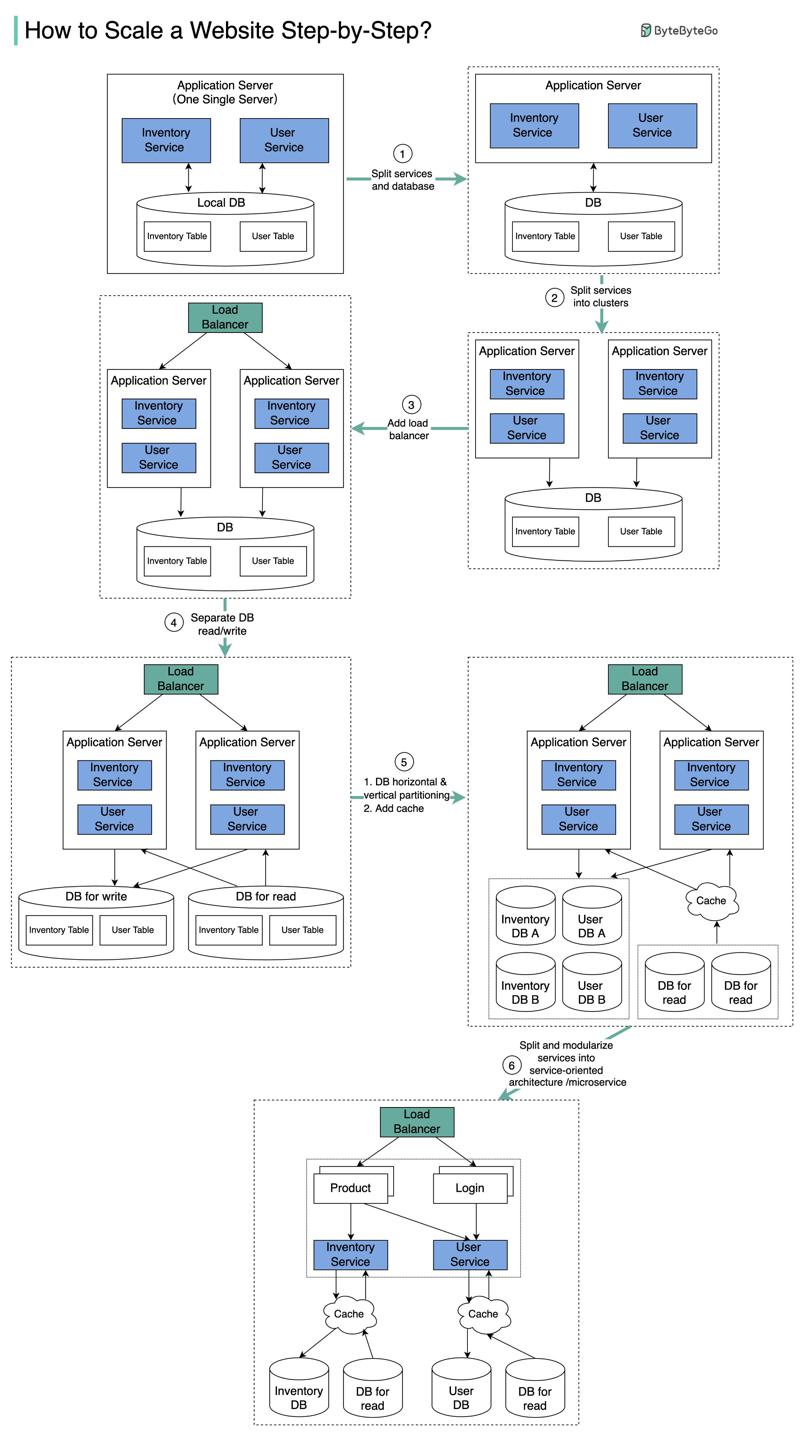
- 由于用户量激增,单个应用后端顶不住流量,我们将应用后端与数据库拆到不同的服务器实例;
- 业务持续增长,我们将应用后端部署为多点集群;
- LoadBalancer负载均衡器处理路由,平衡流量;
- 业务再增长,数据库成为瓶颈,我们开启从库,拆分读写流量;
- 业务再增长,单个数据库实例顶不住TPS压力,现在有几个备选方案:
- 垂直分区:给数据库服务器实例增配,CPU、内存等;
- 水平分区:添加更多服务器实例;
- 增加缓存层;
- 拆分领域服务,微服务架构;
HTTP发展历程
HTTP 1.0 -> HTTP 1.1 -> HTTP 2.0 -> HTTP 3.0 (QUIC). https://twitter.com/alexxubyte/status/1509200416403189765
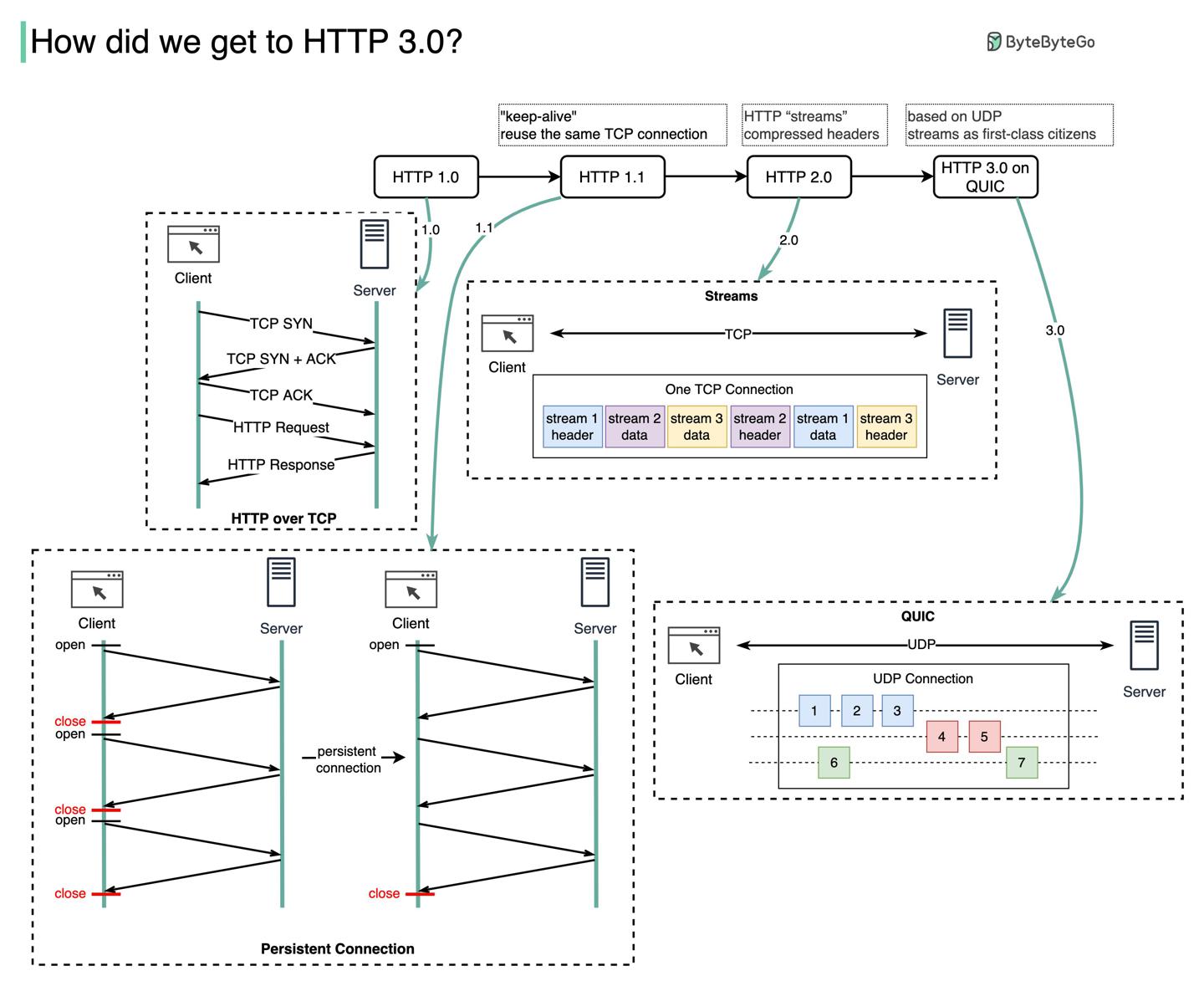
HTTP 1.0
1996年HTTP 1.0敲定了初版,同一服务端的每个请求都需要开启新的TCP连接。
HTTP 1.1
1997年HTTP 1.1发布,TCP连接具备了持久化能力,open之后可复用。HOL(head-of-line)阻塞问题依然存在。
HOL(head-of-line)blocking 当浏览器允许的并行请求量到顶后,后续请求需要阻塞。
HTTP 2.0
2015年HTTP 2.0发布,通过请求多路复用解决了应用层HOL阻塞问题,但传输层TCP依然存在HOL阻塞。
HTTP 2.0引入了HTTP streams 流的概念,允许在同一个TCP连接上多路复用多个请求,并且每个流块不保证有序。
HTTP 3.0
2020年HTTP 3.0首次提案,传输层使用QUIC替代了TCP,因此在传输层解决了HOL阻塞问题。
QUIC基于UDP,其在传输层引入了stream流作为一等公民。QUIC的流复用连接,所以无需多余的握手、创建新连接的开销。
缺点:QUIC的流与流是分开送达的,在很多丢包的场景下,一个流不会影响到别的流。
2013年早期Twitter是如何运行的?
https://twitter.com/alexxubyte/status/1518981294494871553

一条推文的生命周期
- 通过
Write接口发出一条推文; Write服务将请求路由给Fanout service;Fanout service将推文存在Redis,并做一些其他处理;Timeline service找到推文对应时间线所在的Redis实例;- 用户/客户端拉取
Timeline service上的时间线;
搜索 & 发现
- Ingester: 标注、分词推文数据,供搜索用;
- Earlybird: 存储索引;
- Blender: 创建搜索页的时间线;
推送计算
- 基于HTTP推送
- 移动端推送
如何生成全局唯一id?
https://twitter.com/alexxubyte/status/1519348482057797632
研究下像 Facebook, Twitter, LinkedIn 这些亿级用户大厂的用户id是怎么生成的。
需求
- 全局唯一
- 不唯一的话会产生冲突
- 大概按照时间排序
- 像帖子获取的时候有天然的按时间排序的要求,如果id已经经过时间排序,则不需另外的操作
- 只能存number数字类型
- 与时间正相关,方便前端直接获取,无多余排序操作
- 64位
- 32位大概是40亿数据量,对于帖子这类数据来说,id不够用
- 而128位则太大了
- 高拓展性,低延迟
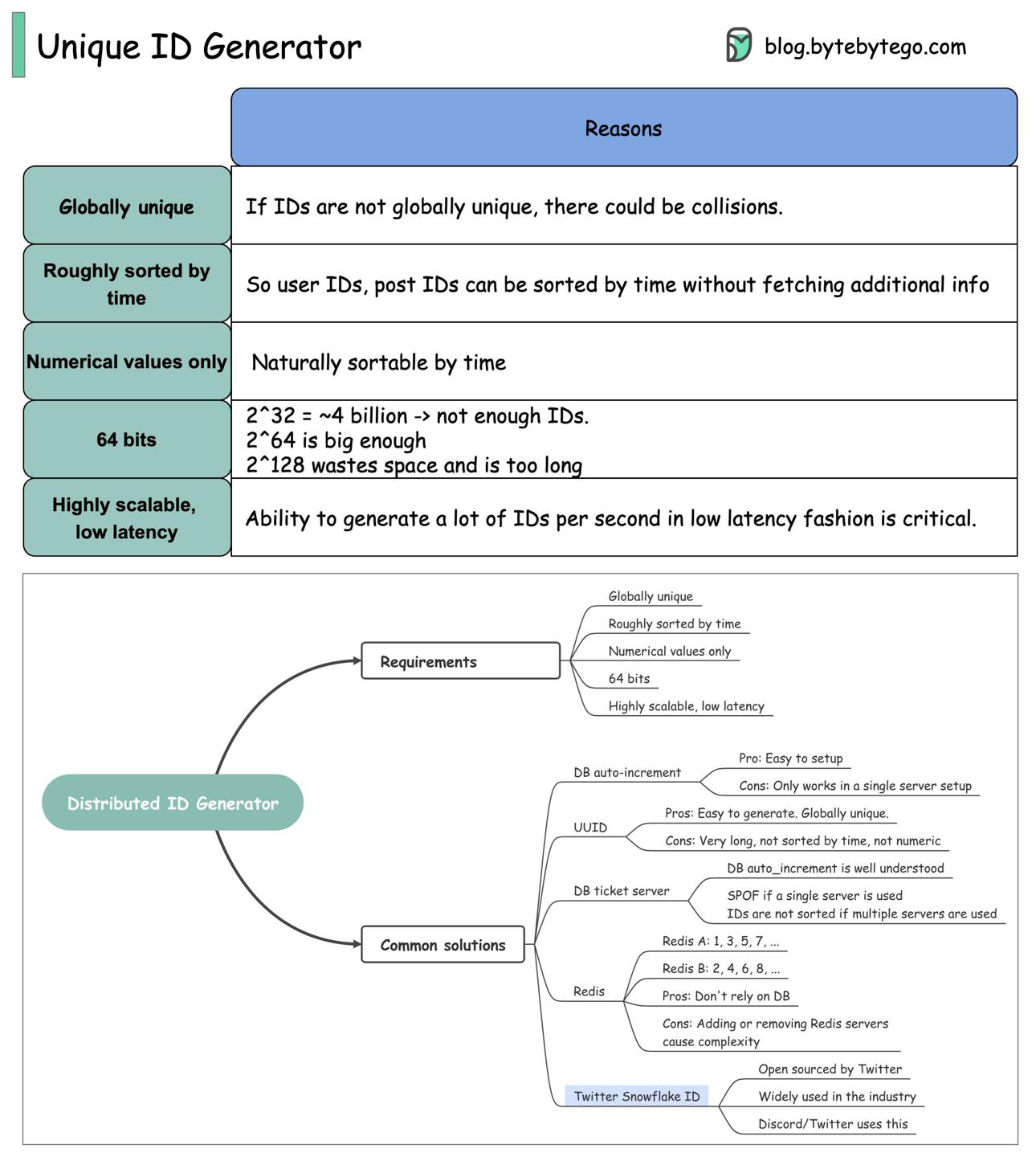
方案对比
| 方案 | 优点 | 缺点 |
|---|---|---|
| 数据库自增id | 维护成本低 | 只能在单点服务架构下可行 |
| UUID | 容易生成;全局唯一 | 太长;非数字;非时间排序 |
| DB ticket server 「我理解就是专用的数据库用于生成id」 | 自增id易理解 | 单点架构下会有单点故障问题;集群架构下id不严格排序 |
| Redis,假设两台,A生成奇数,B生成偶数 | 不依赖数据库 | 引入了Redis集群维护成本 |
| Twitter的雪花算法 | Twitter开源,工业界Discord也用这个方案 |
SSD固态硬盘为什么快?
https://twitter.com/alexxubyte/status/1511374877600595968
背景
固态一般的读写速度是机械硬盘的10-20倍。
解析
SSD是基于flash内存的存储硬件,比特位(数据)存在浮栅晶体管组成的单元格中。相比HDD机械硬盘使用物理磁头,SSD所有组件均为电子组件。
架构
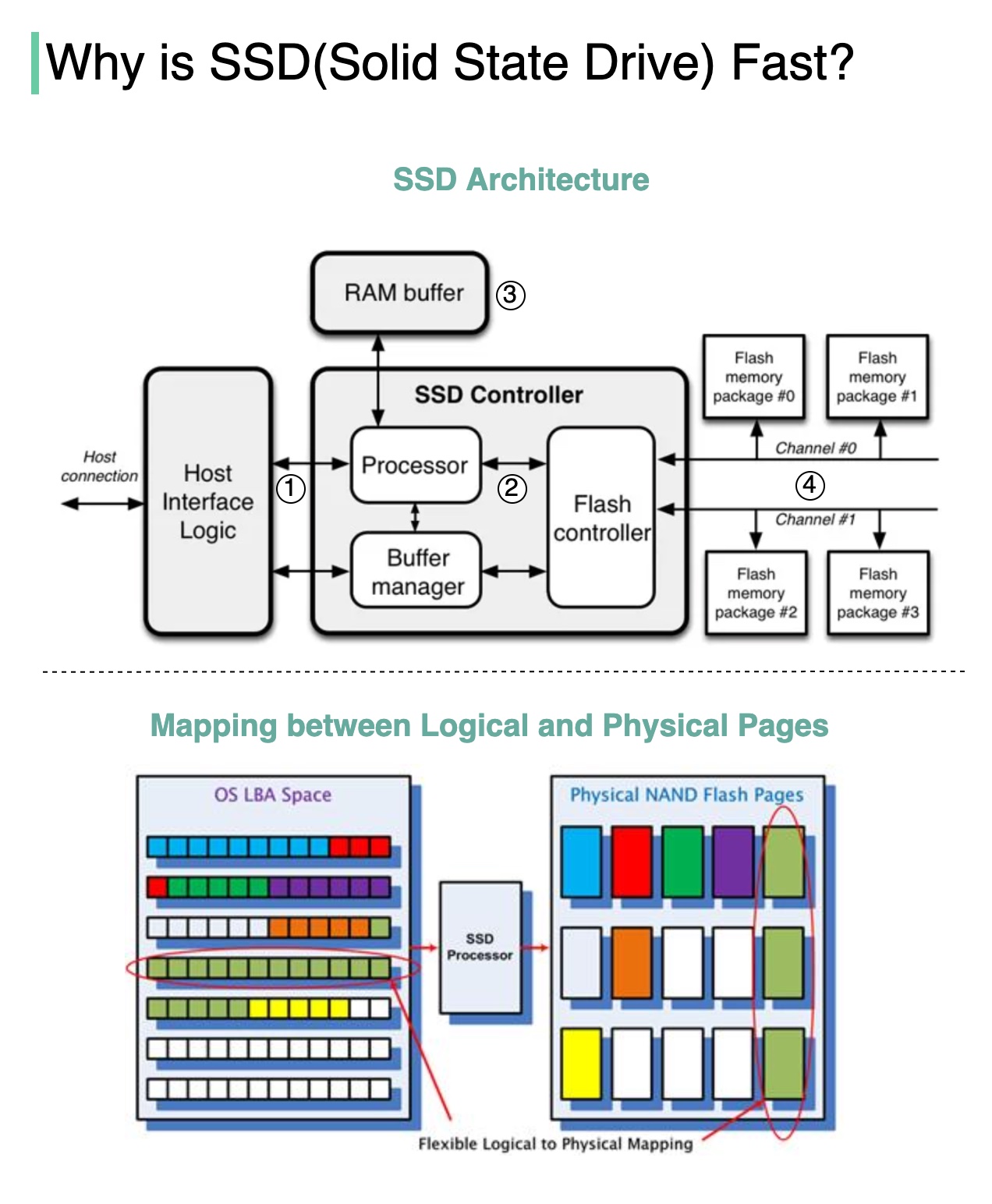
- 用户读写指令通过
host interface传入硬盘,这一层可以使用不同协议:- Serial ATA (SATA)
- PCI Express (PCIe) 提供并行通道能力,更快
SSD Controller中的Processor接管命令,下一步传送给Flash Controller;- SSD内置了
RAM buffer,用于缓存、存储映射信息; - NAND flash驱动内存以组为单位,交给多个
channel管理,可并行处理;
SSD Controller可并行处理多个FLASH颗粒,显著提高了带宽。比如我们想写多个页时,可并行处理。而HDD机械硬盘只有一个物理磁头,同一时刻只能读一个数据。
每次写一个页数据,SSD Controller找到对应物理页、写入、并记录物理页与逻辑页的映射。下次读取数据时,根据映射就能找到数据的具体位置。
Google如何避免爬取重复的URL?
https://twitter.com/alexxubyte/status/1511729406791749634
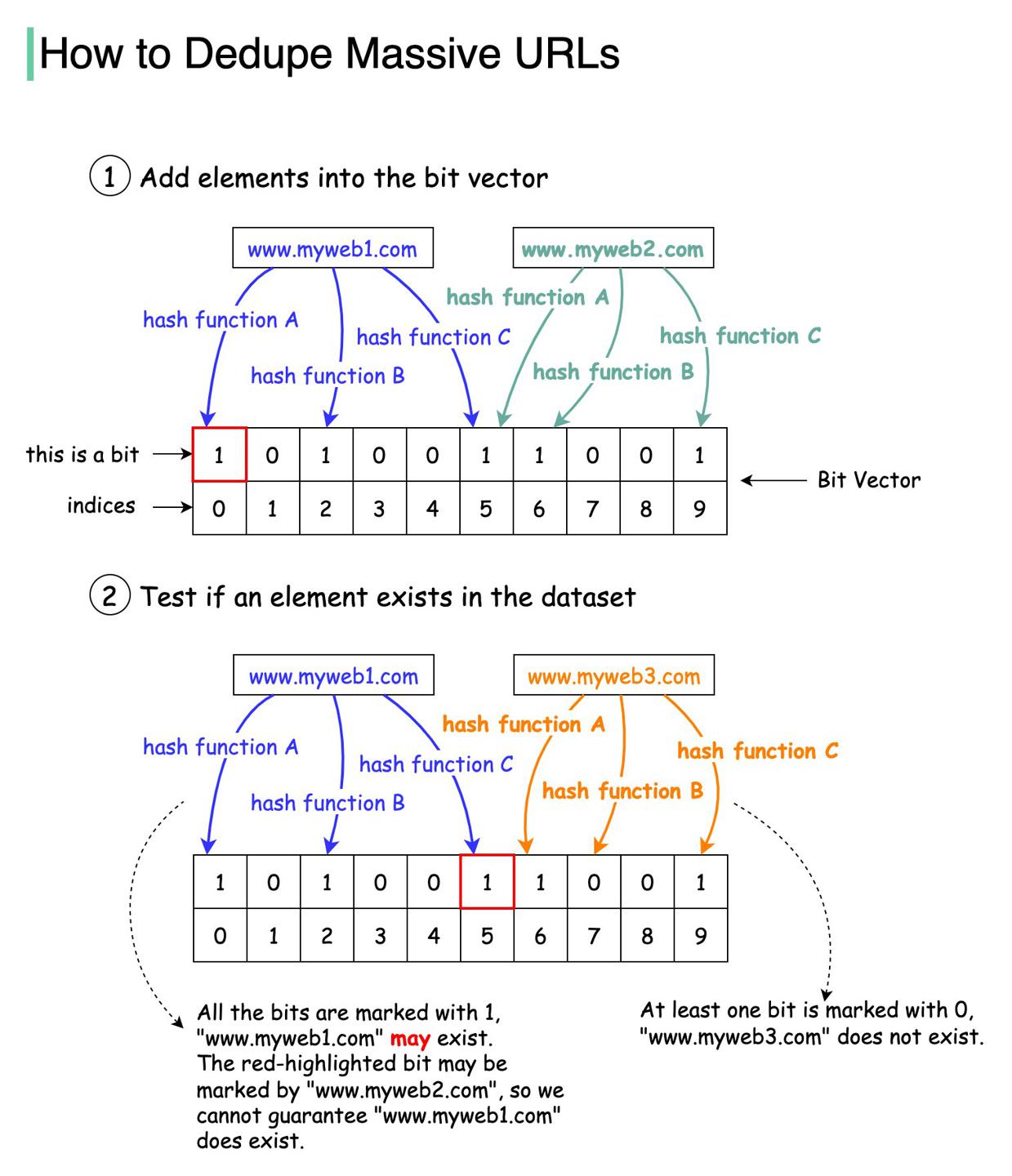
使用set存储爬过的url
set时间效率高,但是空间效率低。
使用数据库存储爬过的url
可行,但是DB负载会很高。
使用布隆过滤器存储爬过的url
这是当前最佳方案。
Bloom filter 在1970年被Burton Howard Bloom提出,是一种概率性数据结构,可以用来判断元素是否在集合中。
- false
- 表示元素一定不在集合中
- true
- 表示元素可能在集合中
底层为一个位图,bitmap中存储元素经过多个hash函数计算后的槽位。
bloomfilter还有升级版的布谷鸟过滤器,可以参考 linvon博客:布谷鸟过滤器:实际上优于布隆过滤器。
虚拟化与容器化的区别?
https://twitter.com/alexxubyte/status/1512453102380908546
解析虚拟化(VMWare)与容器化(Docker)的区别。
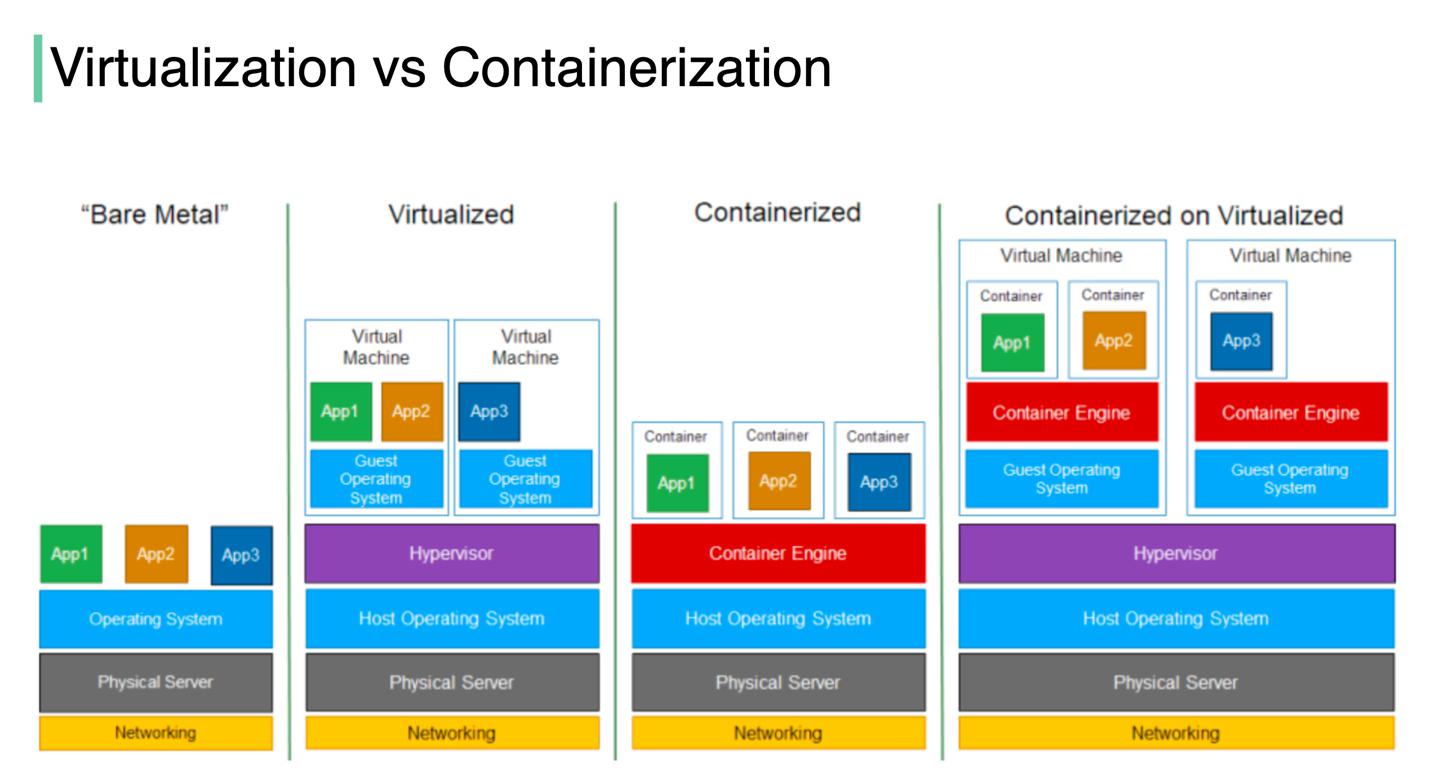
虚拟化
虚拟化技术可以让我们在单一硬件上生成多套虚拟环境。
容器化
容器化则是将程序源码、依赖的库或者框架一同打包,所以每套容器都是隔离的。
对比
- 虚拟化技术中,Hypervisor在硬件之上提供了一层抽象,所以多套系统可以同时运行在同一套硬件上。这也是云计算的第一代思想。
- 容器化则是轻量级的虚拟化,在操作系统之上提供一层抽象,因为没有Hypervisor中间层,容器操作资源更加高效。
如何设计接口鉴权?
https://twitter.com/alexxubyte/status/1514256018187816965
背景
openAPI需要保证接口经过鉴权。
方案
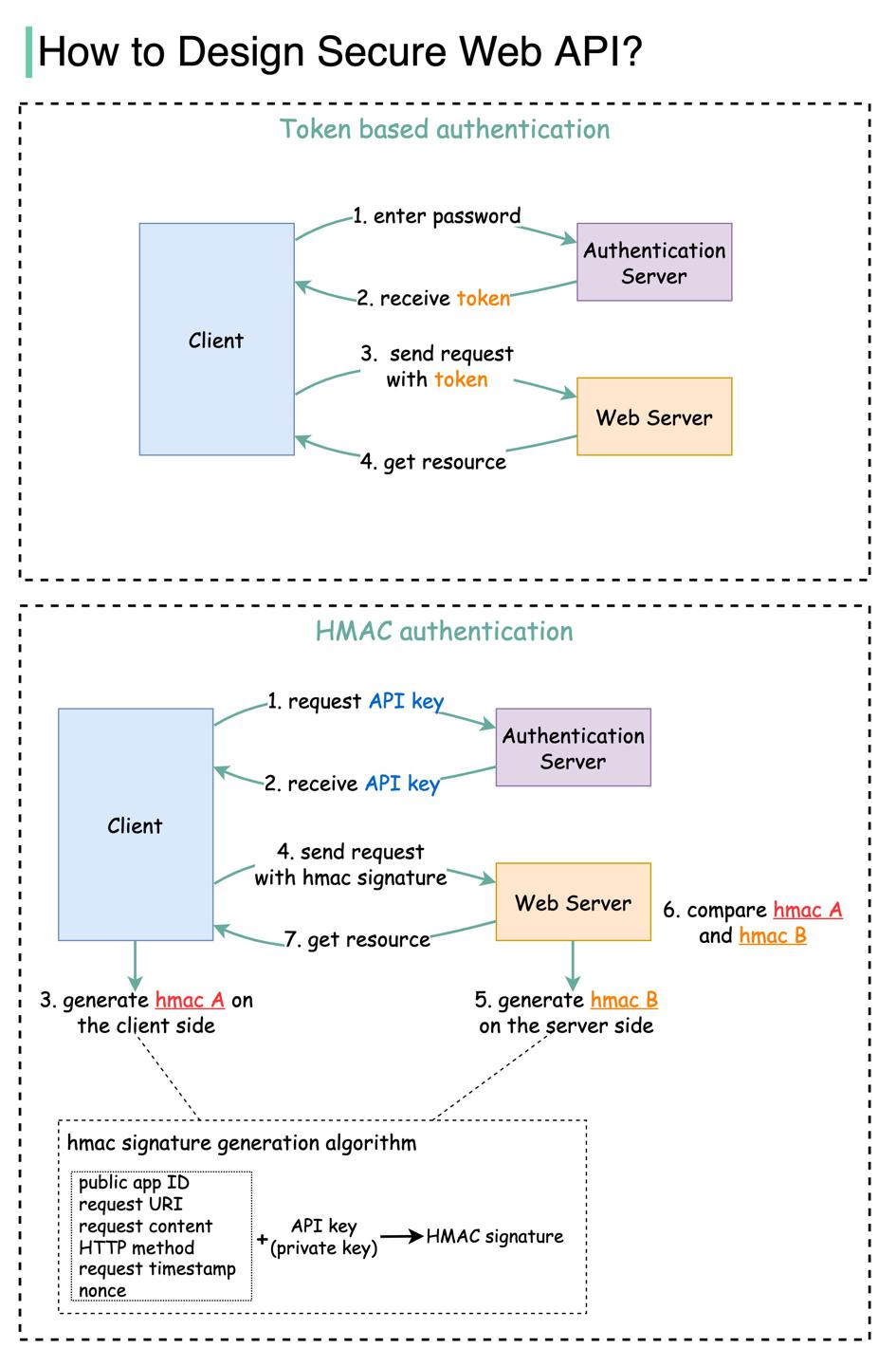
最常见的方案:
- 基于
Token;- 用户在客户端输入密码,向鉴权服务端请求返回
token; - 鉴权服务端生成并返回
token,同时设定有效期; - 与下一步合并;
- 客户端在
HTTP Header携带token请求资源;
- 用户在客户端输入密码,向鉴权服务端请求返回
- HMAC (Hash-based Message Authentication Code) 基于哈希消息;
- 与下一步合并;
- 鉴权服务端生成:
- public的appID;
- private的apiKey;
- 客户端根据以下属性生成hmac哈希码,hmacA:
- appID
- 请求uri
- 请求内容
- HTTP方法
- 请求时间戳
- apiKey
- 客户端在
HTTP Header携带hmacA请求资源; - 我们的web后端也根据第三步的哈希算法计算出签名:hmacB;
- 与下一步合并;
- 根据hmacA、hmacB是否相等决定鉴权结果;
如何发布部署服务?
https://twitter.com/alexxubyte/status/1516444237440512007
背景
部署、升级服务有很大风险,需要提前考虑风险缓解策略。
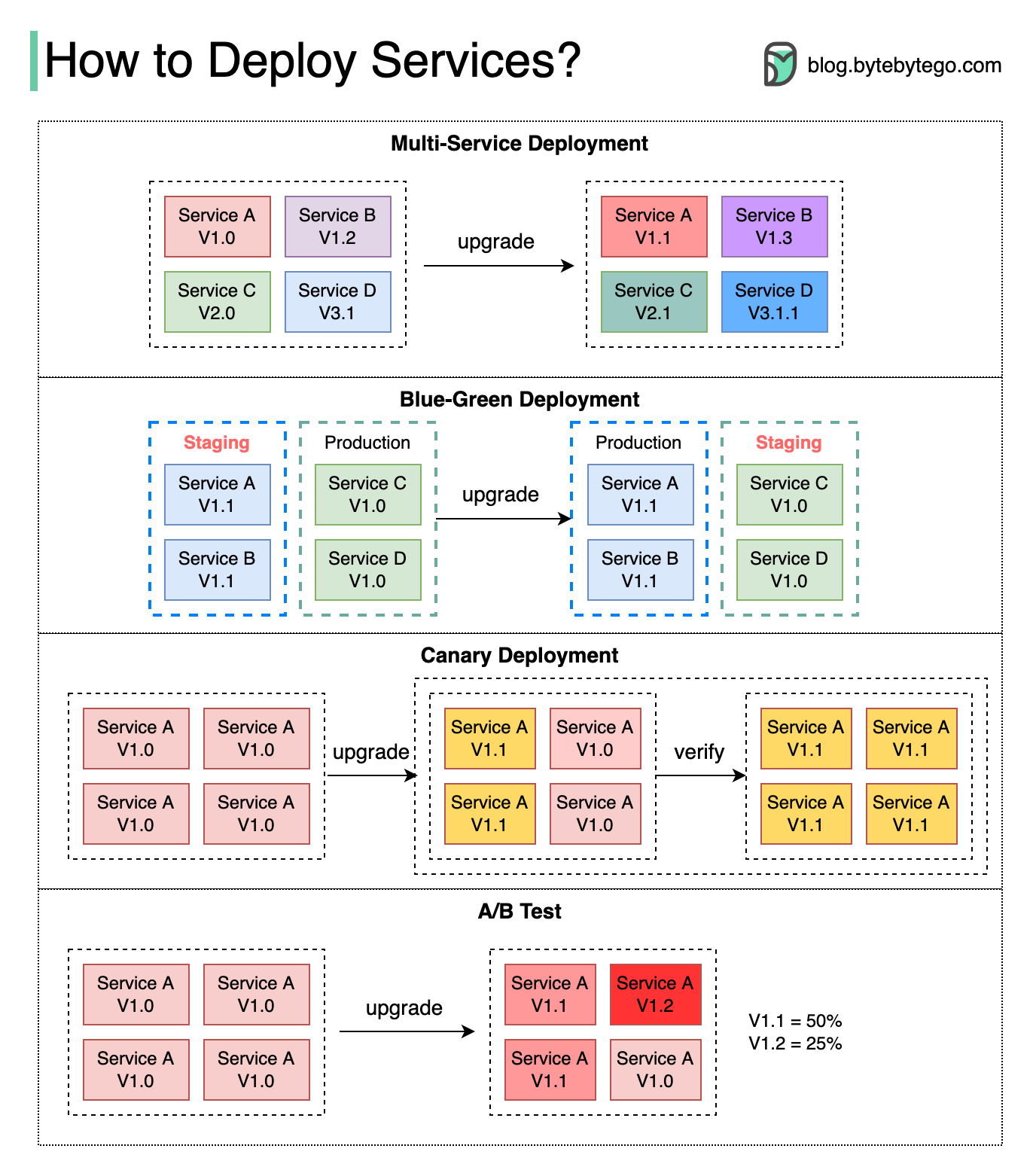
𝐌𝐮𝐥𝐭𝐢-𝐒𝐞𝐫𝐯𝐢𝐜𝐞 𝐃𝐞𝐩𝐥𝐨𝐲𝐦𝐞𝐧𝐭 多服务同时发布
同时部署多个服务是最容易实现的,但是管理、测试依赖项、回滚成本会比较高。
𝐁𝐥𝐮𝐞-𝐆𝐫𝐞𝐞𝐧 𝐃𝐞𝐩𝐥𝐨𝐲𝐦𝐞𝐧𝐭 蓝绿发布
启动两个一模一样的环境:
- staging「blue」
- 前置环境
- production「green」
- 后置环境
staging测试完成后,将流量切换到切到staging,此时staging变成了production。
这种方案很好回滚,但是使用两个一模一样的生产环境成本较高。
𝐂𝐚𝐧𝐚𝐫𝐲 𝐃𝐞𝐩𝐥𝐨𝐲𝐦𝐞𝐧𝐭 灰度发布
灰度部署会逐步发布多个服务,每个批次针对流量子集。
优点
相比蓝绿发布成本较低。同时回滚成本也很低。
缺点
- 由于没有
staging环境,必须在生产环境测试。 - 实现难度高,需要监控灰度过程,流量切换需平滑。
𝐀/𝐁 𝐓𝐞𝐬𝐭 AB测试
同时在生产环境运行服务的新旧版本,每个版本针对部分子集用户。
AB测试的测试成本更低。
关于Amazon的部署相关文档参考这里:确保部署期间安全回滚。
如何设计 Google Docs 在线文档?
https://twitter.com/alexxubyte/status/1516806335303536642
流程解析
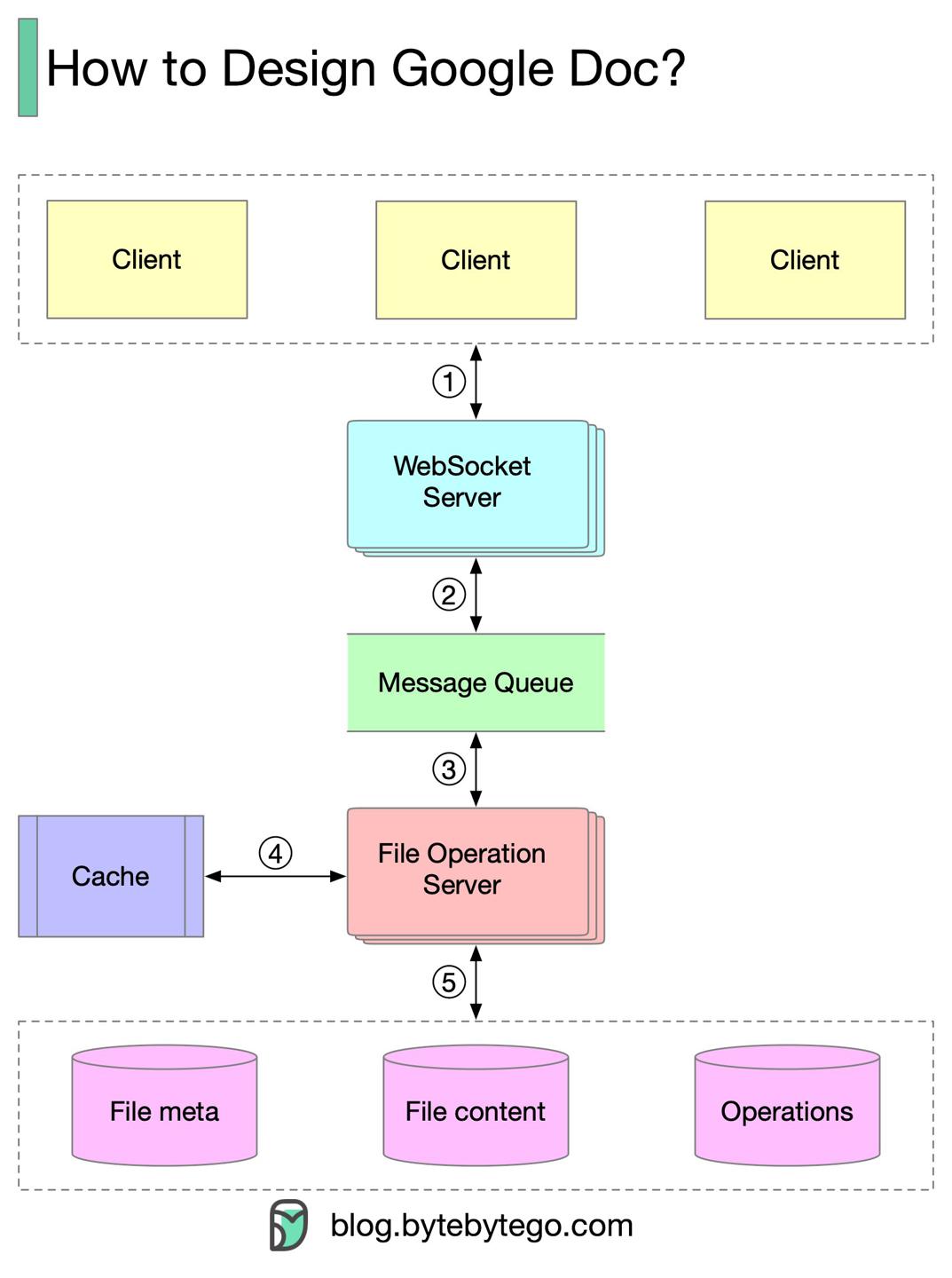
- 客户端给
WebSocket服务端发送文档编辑操作; WebSocket服务端负责实时通信;MQ负责存储文档操作;- 文档操作服务端消费消息,使用协作算法转换操作信息:
- 文档操作服务端存储:
- 文档元信息;
- 文档内容;
- 操作;
核心挑战
实时的冲突解决是很大的问题,主流算法:
- Operational transformation (OT)
- Google Doc 使用这种算法;
- Differential Synchronization (DS)
- Conflict-free replicated data type (CRDT)
- 适用于实时并发编辑场景;
进程与线程的区别是什么?
https://twitter.com/alexxubyte/status/1518615214316425216
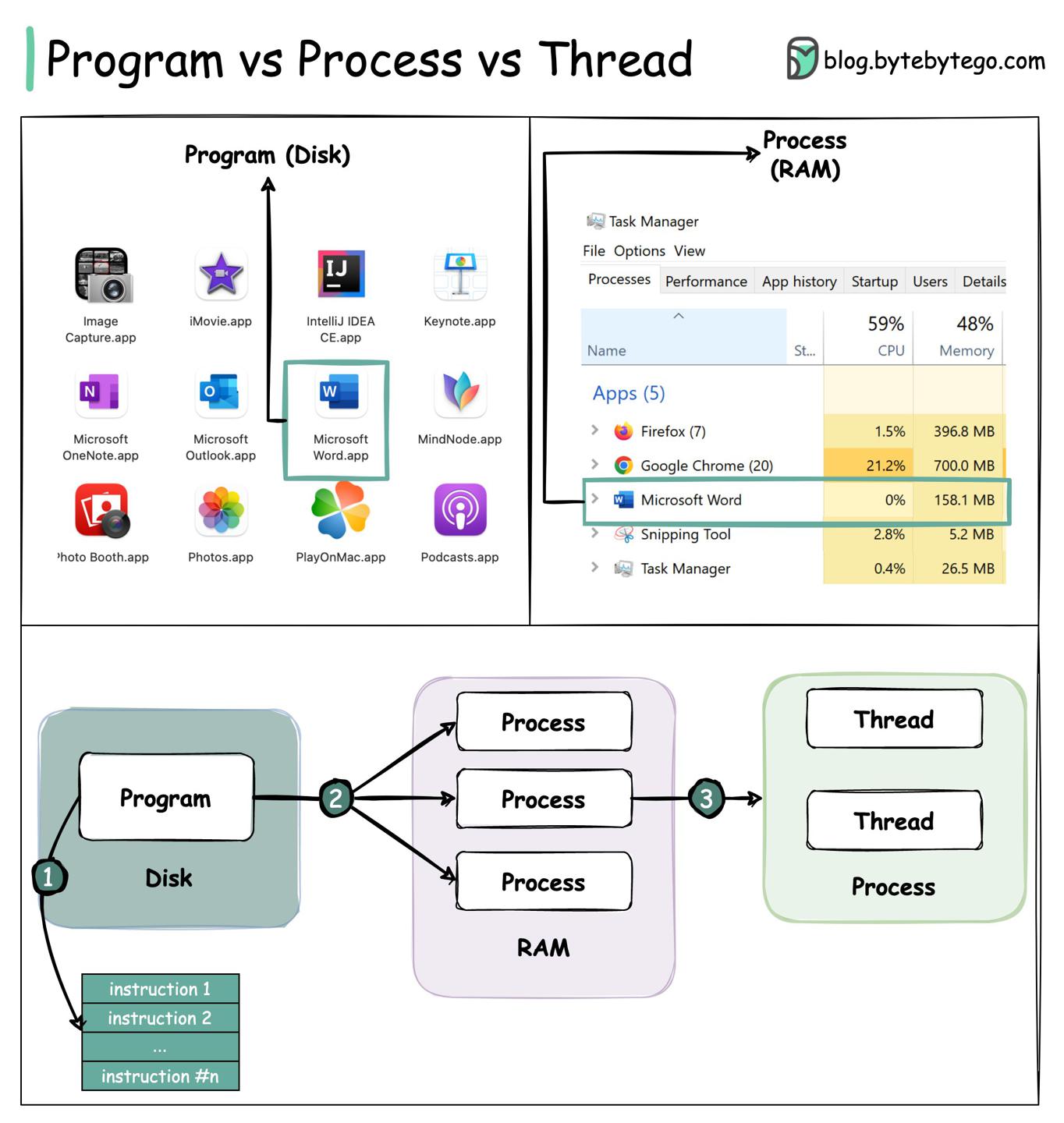
Program
程序 program 是一个保存在磁盘的可执行文件,内部包含一系列指令。一个程序可以对应多个进程,比如Chrome的每个tab都是一个进程。
Process
一个进程 process 意味着程序在运行态。当程序加载到内存进入活动态,程序就变成了进程。进程持有一些核心资源:
- 寄存器
register - 计数器
program counter - 栈
stack file handlessocketsdevice handles
Thread
线程是进程运行的最小单位。
编程语言级别的线程对应一个内核态的线程。OS scheduler为线程抢占式分配时间片,提供并发功能。多线程可运行在多处理器上。
Coroutine
像Golang、Kotlin这种语言支持了协程 coroutine,协程是封装级别更高的api,内部依然是线程池,程序员使用编程语言调度协程,函数内决定并发任务何时暂停、继续。
协程相对来说更轻量级,使用更小的开销(没有OS scheduler调度的开销),实现了并发的语义。
对比
- 进程通常是独立的,而线程作为进程的子集存在;
- 每个进程拥有子集的内存空间,而线程与进程共享内存;
- 进程操作相对重量级:
- 创建、终止开销较大;
- 上下文切换开销较大;
- 线程间通信效率更高;
- 协程相对更轻量级:
- 比线程使用更少内存,每个线程需要单独的栈空间,协程则不是;
- 没有系统调度开销;
发送邮件背后发生了什么?
https://twitter.com/alexxubyte/status/1501963751397871625
解析赵四给刘能发送邮件背后的过程。
赵四对应Alice
刘能对应Bob
用户主流程
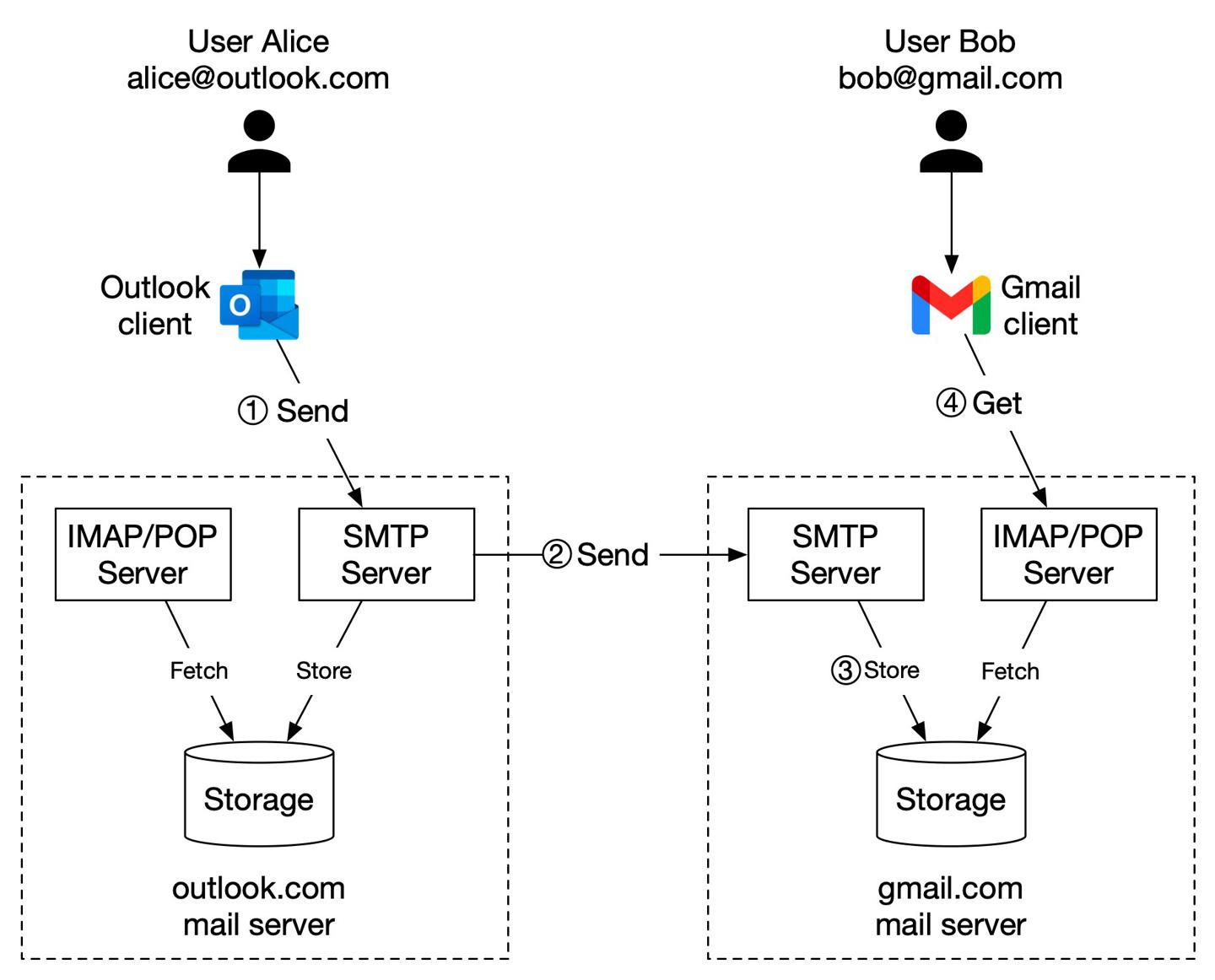
- 赵四登录他的
Outlook客户,写好邮件,点击发送。邮件首先发到Outlook服务端,客户端与服务端交互的协议为SMTP; Outlook服务端查一遍DNS,找到刘能的SMTP服务地址「Gmail」,将邮件发给Gmail服务端;Gmail服务端存储邮件内容,此时刘能可以查到邮件;- 当刘能打开手机
GmailApp时,客户端使用IMAP/POP协议从服务端拉取邮件;
邮件发送流程
https://twitter.com/alexxubyte/status/1488195702308040704
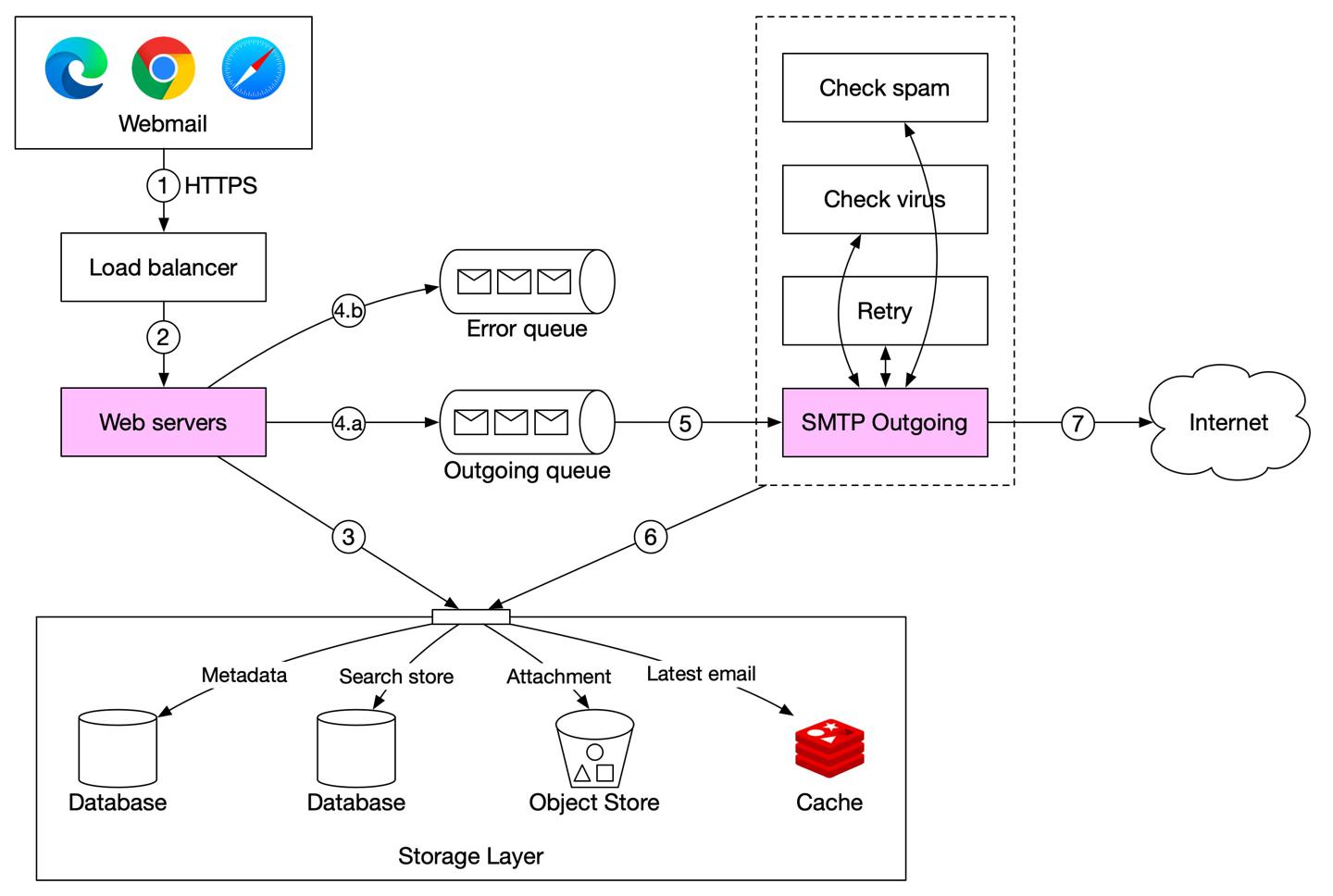
- 赵四写好邮件,发送,请求首先经过负载均衡器
load balancer; load balancer处理一些限流、路由逻辑,请求转给web后端;- web后端处理:
- 校验
- 检查接收人邮箱地址是否与发送人一样,如果已有就直接存储,此时用户直接通过
RESTful接口查到邮件,不需后续流程
- 消息队列
- 基础校验通过后,邮件被放入
outgoing队列 - 校验未通过,邮件被放入
error队列
- 基础校验通过后,邮件被放入
SMTPworker从outgoing队列拉取邮件,并且判定是否有垃圾邮件、病毒outgoing邮件存储在已发送文件夹下SMTPworker发送邮件给接收者服务端
要点:
outgoing队列中的每条消息都携带了创建邮件所需的元信息- 分布式mq对于异步邮件处理是很重要的组件
- 需要仔细检查
outgoing队列中的消息量,一旦有大量邮件阻塞,需要分析原因:- 接收人的服务端不可用了,这种情况一般过段时间进行重试,指数型补偿是不错的重试策略「1,2,4,8逐步变慢节奏」
- 负责发邮件的消费者不够了,这种情况需要增多消费者
邮件接收流程
https://twitter.com/alexxubyte/status/1488561820423970820
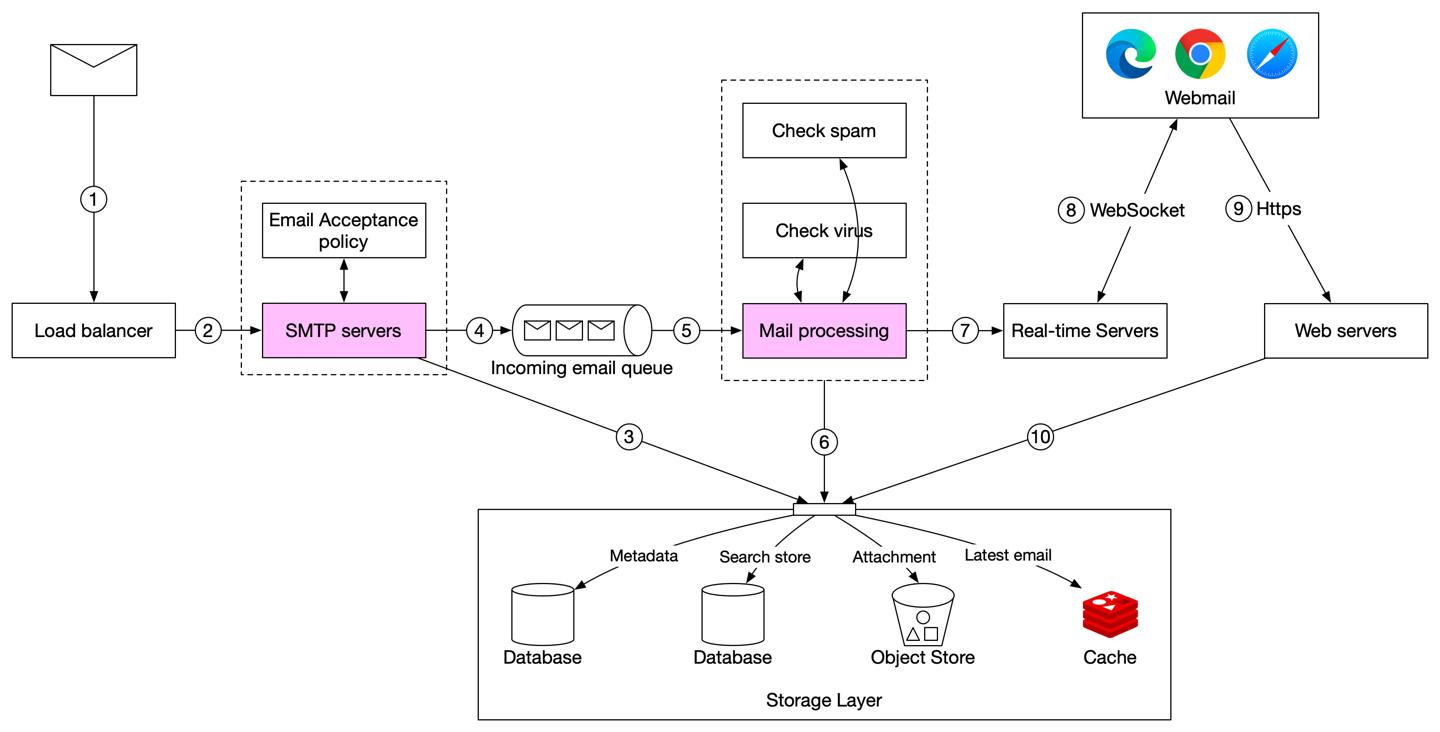
- 赵四那边发来的邮件首先经过
SMTPload balancer load balancer在SMTP服务器间做流量负载,在SMTP连接级别可以配置邮件接收策略,在这一步,非法的邮件被拦截- 如果附件过大,会将附件放到附件存储
- 邮件被放入接收邮件队列
- 队列将邮件处理与
SMTP服务端解耦,两端可根据对应负载进行拓展 - 队列在邮件量激增时,扮演了缓存的角色
- 队列将邮件处理与
- 邮件处理
worker处理多种逻辑:过滤垃圾邮件、拦截病毒 - 邮件信息存在数据库、缓存、对象存储等多种介质中
- 如果刘能这时候在线,邮件会直接推给实时服务端
- 实时服务端使用
WebSocket协议,刘能可以直接感知到邮件变化 - 如果刘能这时候离线,邮件存到存储层,当刘能打开客户端上线后,
webemail客户端使用RESTful连接到服务端,将邮件从存储层拉到客户端
设计一个指标收集、监控、告警系统
https://twitter.com/alexxubyte/status/1481679754008825857
背景
收集指标、监控、告警,是分布式架构系统中保持高可用非常重要的一环。
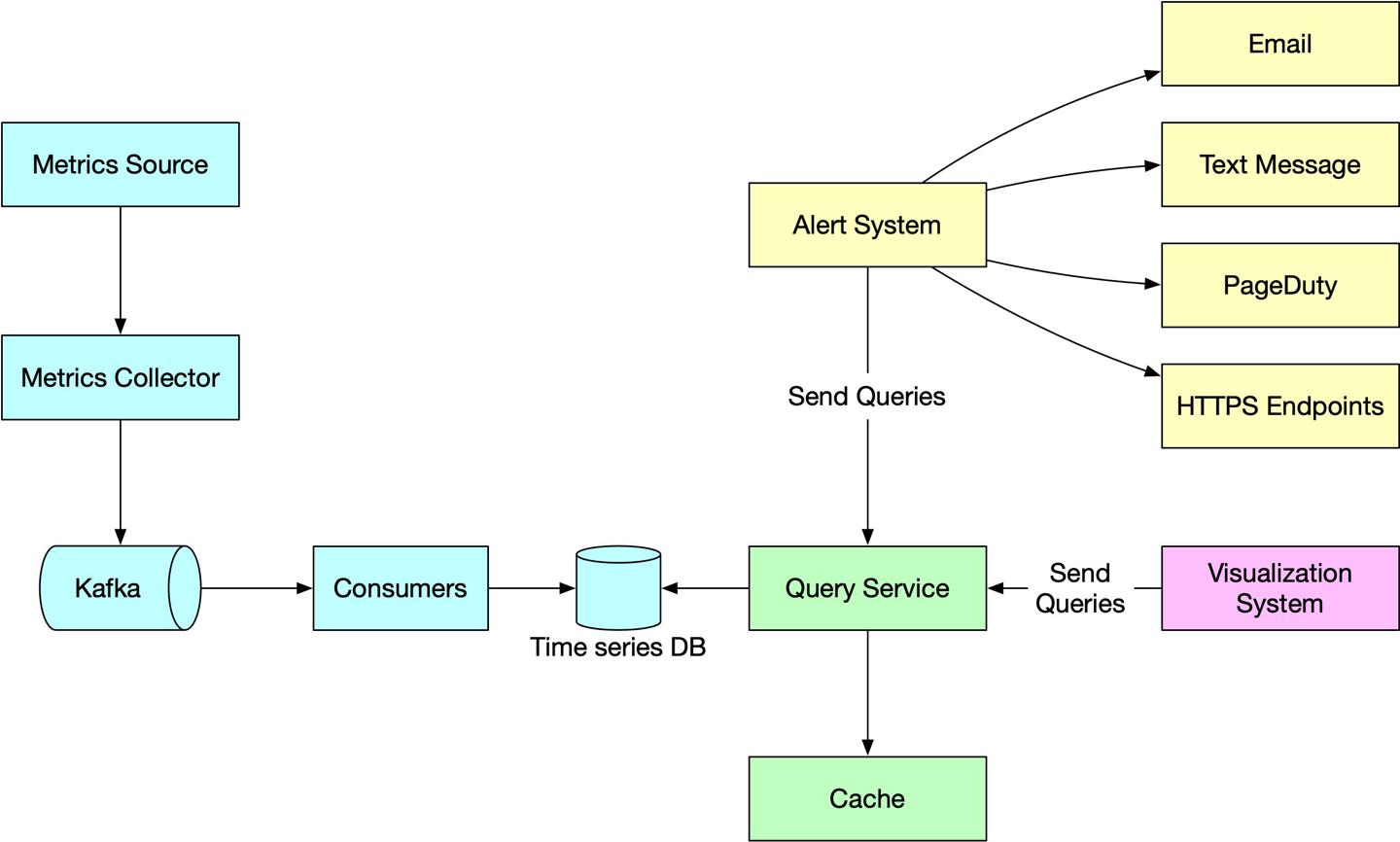
方案
Metrics source 指标源
- 应用服务
- 数据库
- 消息队列
Metrics collector 指标收集器
- 收集指标数据,将其写入 tsdb 时序数据库
Ref
https://twitter.com/alexxubyte/status/1484578136842850312
pull收集方式
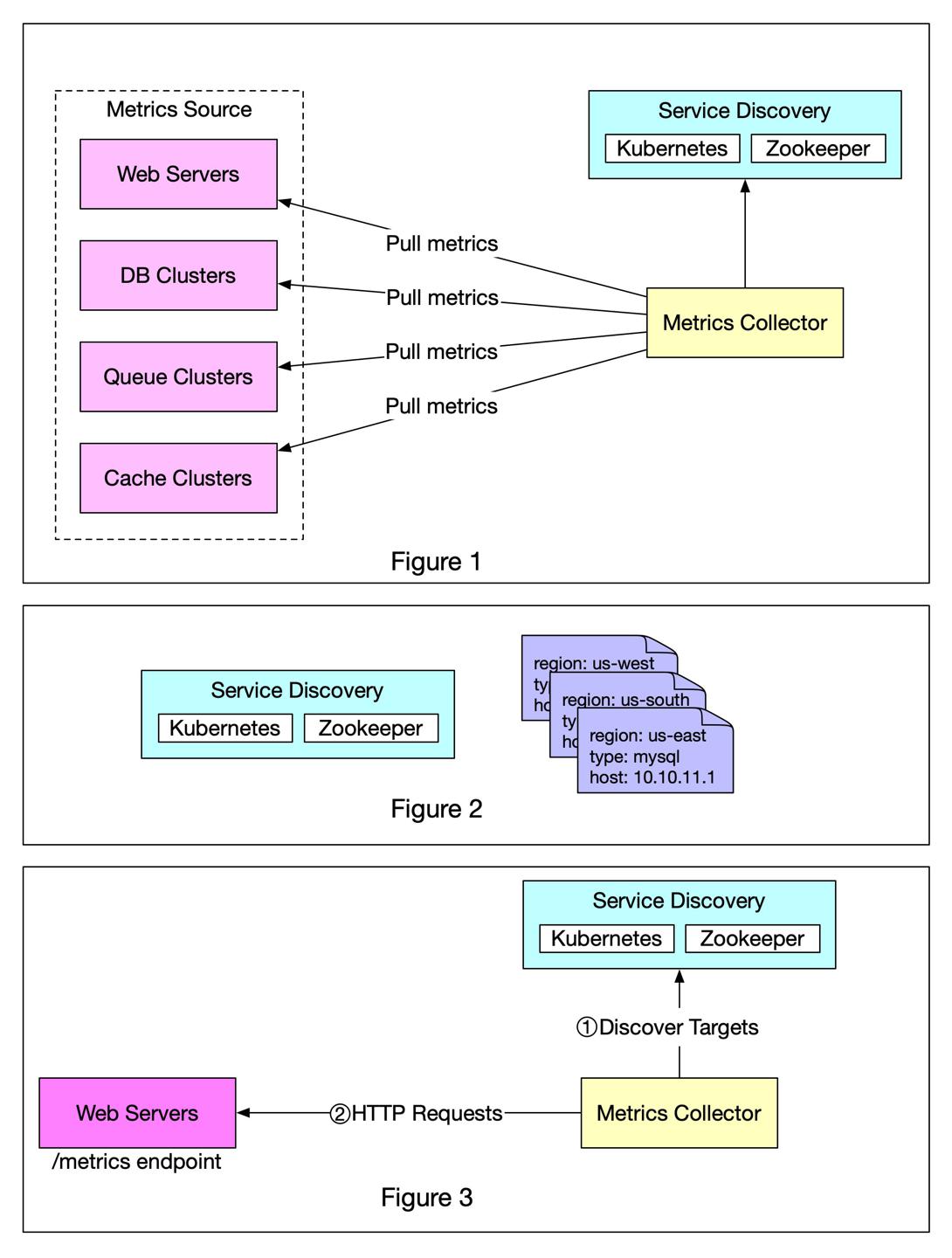
要点:
- 定期拉取
- 专门的组件负责
- 使用
HTTP协议从source拉取 - 服务发现
- 简单场景下我们只需一个文件来维护
source的地址信息,少量变更时也可以通过手工修改文件进行服务的上下线 - 复杂情况下我们需要服务发现组件,来帮我们自动更新、通知服务的变更
- Kubernetes, Zookeeper
- Figure 3 解释了注册服务、更新服务、拉数据的过程
- 通过服务发现组件拉取服务端的配置元数据(pull需要的内部信息)
- ip地址
- 超时时间
- 重试参数
- etc
- 通过预定义的
HTTP接口拉取数据,如/metrics- 可通过依赖、库的方式暴露对应
endpoint - 如 Figure 3 ,对应拉取的服务是一个web后端
- 可通过依赖、库的方式暴露对应
- 可选项:collector注册服务变更通知
- 当服务
endpoint变更时可自动更新接口信息 - 最简单的方式就是定期轮询
- 当服务
- 通过服务发现组件拉取服务端的配置元数据(pull需要的内部信息)
- 简单场景下我们只需一个文件来维护
push收集方式
tbd
Time-series database 时序数据库
- 以时间序列存储归集数据
- 提供UI界面,供分析、聚合数据
- 基于
label创建索引,加快label维度的聚合查询 - 实例:prometheus
Kafka
- 一款高可用、支持大数据拓展的分布式消息平台
- 将数据收集、数据处理解耦
Consumers
- 消费者通常使用流式系统,如
Apache Storm, Flink and Spark,下一步将数据推到tsdb
Query Service 查询服务
- 作为UI系统,方便用户从
tsdb查询数据 - 可以内部做一层简单封装转发,也可以使用
tsdb提供的界面系统
Alerting system 告警系统
- 向多个系统发送告警通知
Visualization system 可视化大盘系统
- 以图表的方式展示指标
如何解决对账问题?
https://twitter.com/alexxubyte/status/1480957044047835141
背景
在支付系统中,对账是比较繁琐、痛苦的一个环节,服务目标是对齐不同系统间的金额,过程中会产生很多复杂问题。
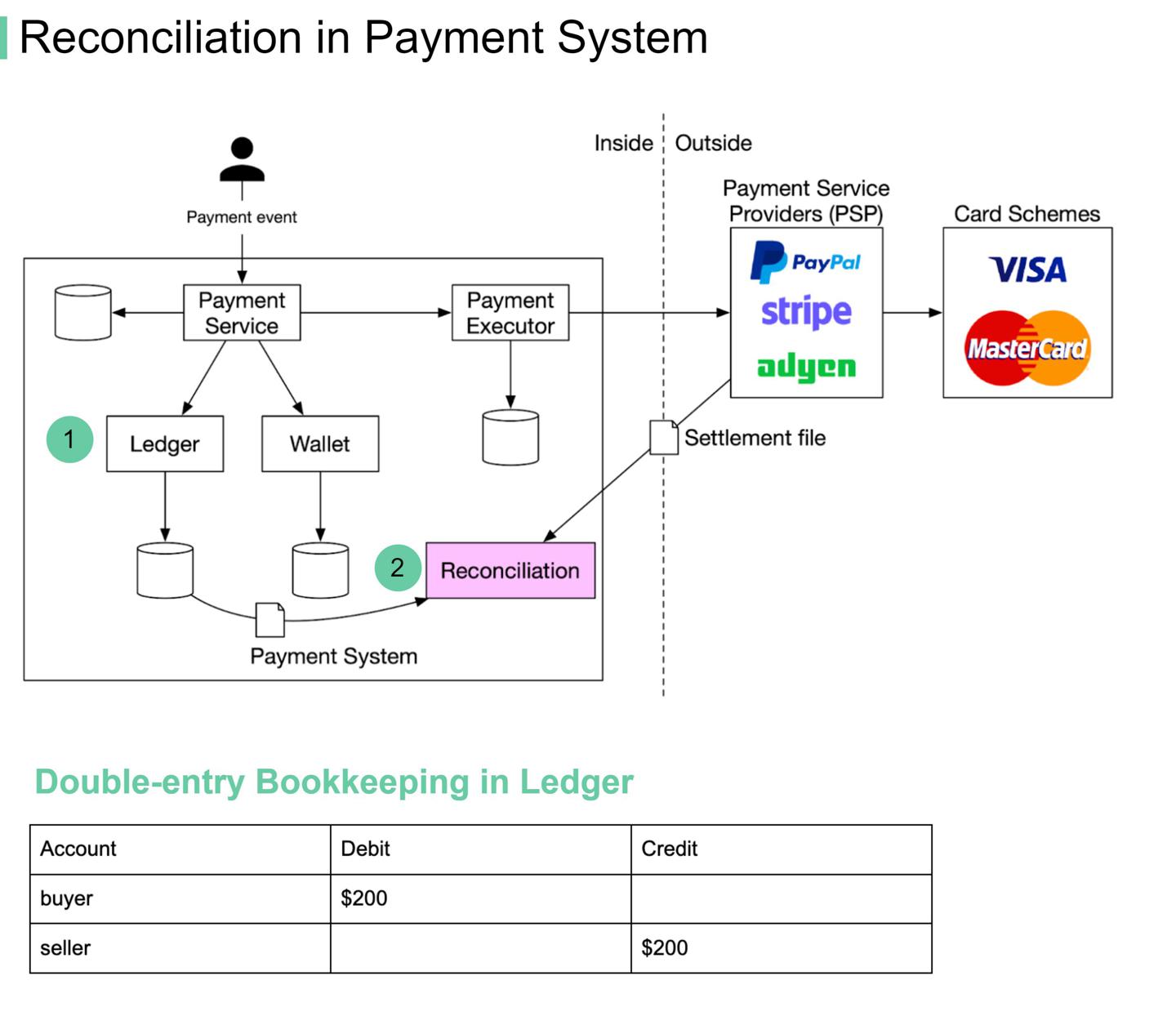 比如我们使用
比如我们使用PayPal买了一块200的表:
- 电商网站应该会记录一笔200金额的订单;
- 同时生成一条与
PayPal的交易账单; - 总账服务会为买方记录一笔200的借记出账,为卖方记录一笔200的入账,此为「复式簿记」
double-entry bookkeeping;
问题
数据标准化
在不同系统间对比数据时,数据格式不同。
解决:增加一个转换层转换格式。
大数据量
解决: 针对不同量级的数据量,我们可以考虑:
- 定时分批处理;
- 流式系统近实时计算;
- 其他大数据技术栈;
临界时间问题
假设我们约定 00:00:00 为一天的起始时刻。
- 内部系统我们记录时间:23:59:55 ;
- 外部系统记录时间:00:00:30 ;
此时两个系统比对数据时,在同一天中数据不匹配了。
解决:内部服务在当天批次查不到数据时,跳跃到第二天的批次拉取数据。如果还是找不到,忽略这种数据。
支付系统设计索引
- Payment system
- Payment security 安全风控
- Double charge 多次收费
- Reconciliation 对账
- Painful payment reconciliation
- Clearing & settlement 清结算
- Foreign exchange 跨境交易
- SWIFT
PDF link: https://bytebyte-go.s3.amazonaws.com/LinkedInPDF_part1_payment+-+Google+Docs.pdf
设计一个基本的股票交易系统
https://twitter.com/alexxubyte/status/1478796978238615553
方案
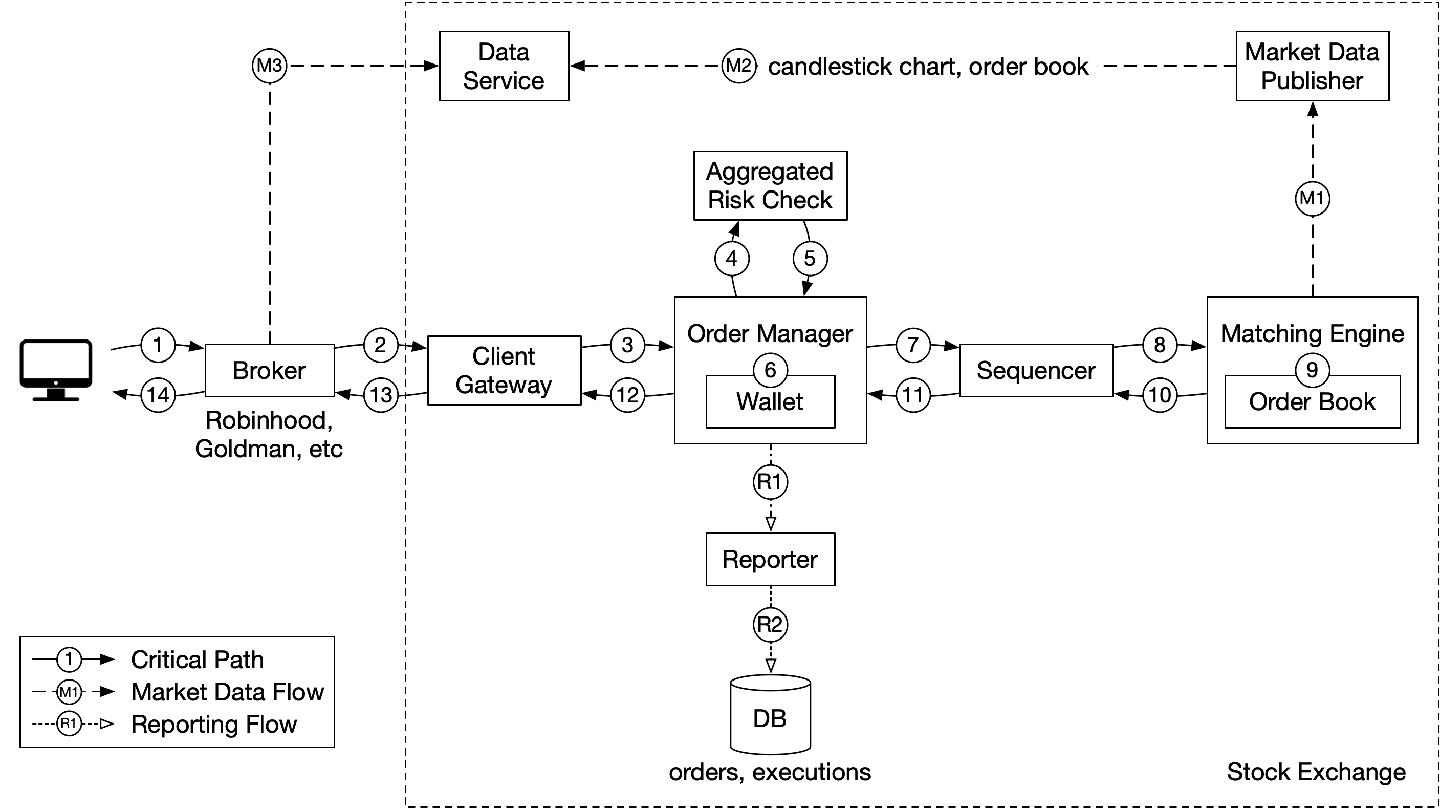
用户过程解析:「关键路径:交易」
- 用户通过交易前台下单
- 前台发送订单给交易后端「1/6」
- 网关层执行:
- 校验
- 限流
- 认证
- 标准化处理
- 发送订单给订单服务
-- 4/5步校验风控规则「2/6」
- 检查钱包余额
--- 订单交给匹配引擎。匹配引擎将匹配到的结果返回
----- 匹配结果一路返回给用户前台
市场数据过程解析:
- M1-M3 发送市场数据给数据服务,包括阴阳烛图(K线)、订单,前台broker通过数据服务查询数据
报表过程解析:
- 报表服务组合需要的报表字段,处理对应后端逻辑
设计解析
- 交易为关键路径,相对来说市场数据、报表则不关键,对应我们系统设计的延迟要求不同
如何避免多次收费?
https://twitter.com/alexxubyte/status/1478409566463291395
背景
支付系统设计实操中,面对一个常见的问题:对用户发起了多个收费。
我们的系统需要做到exactly-once的语义。
方案
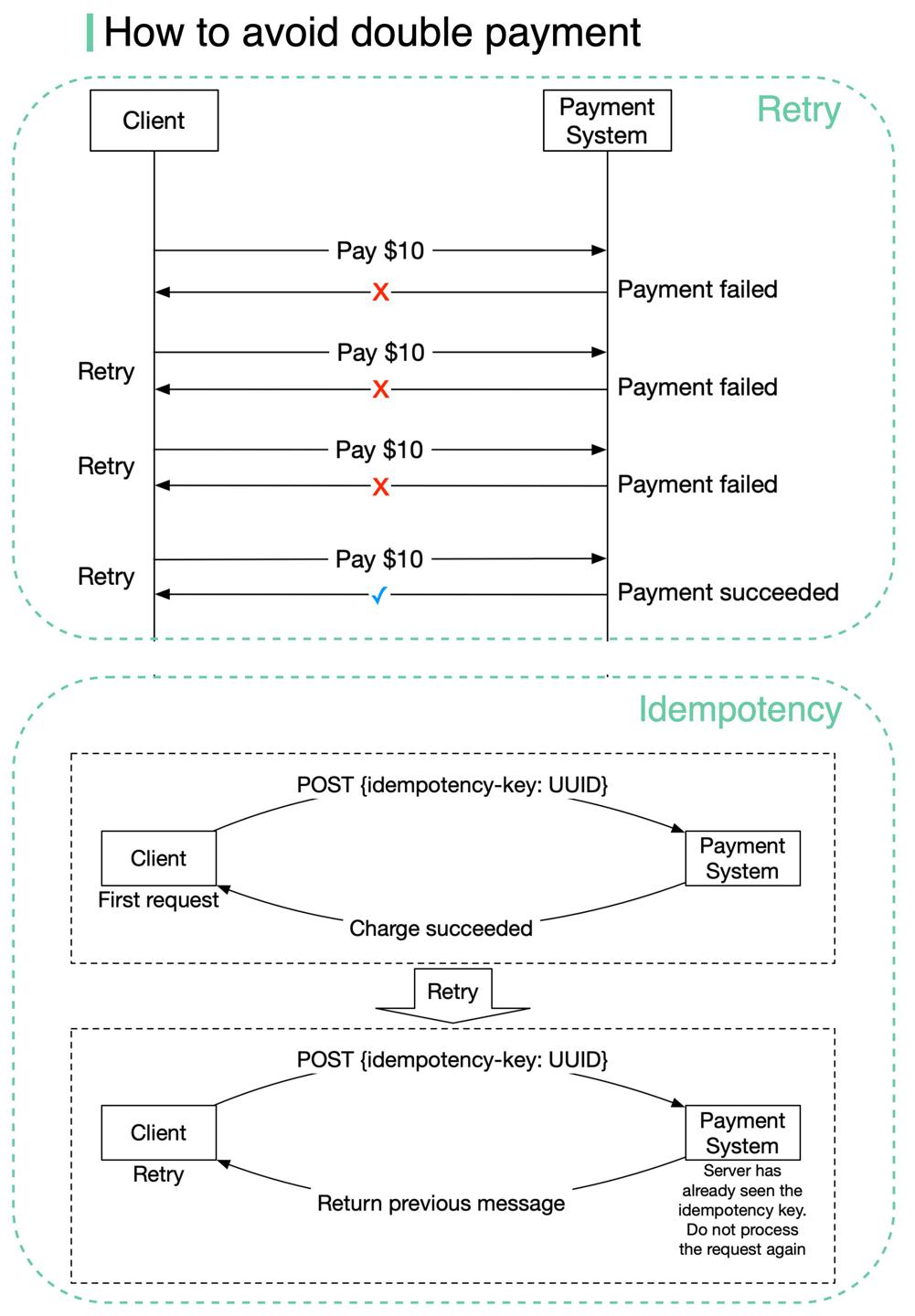
拆解exactly-once语义:
- 请求至少执行一次,即
at least once - 同时满足,执行最多一次,即
at most once「2/6」
分别对应两种手段:
Retry重试- 重试可以解决网络错误、超时等问题,保证了至少一次的语义「3/6」
idempotency check幂等校验- 幂等是接口设计的常见方案,客户端可以针对同一请求重复发起多次,并且保证了最终结果是一致的「4/6」
- 在端与端间的网络通信中,幂等的key一般由客户端生成,并且在特定时刻失效,具有唯一性
- 在
StripPayPal等公司,通常使用了UUID作为了这个幂等唯一键,放在HTTPheader中「/66」
- 在
电商购买按钮背后做了什么?
https://twitter.com/alexxubyte/status/1478059800453779456
过程解析
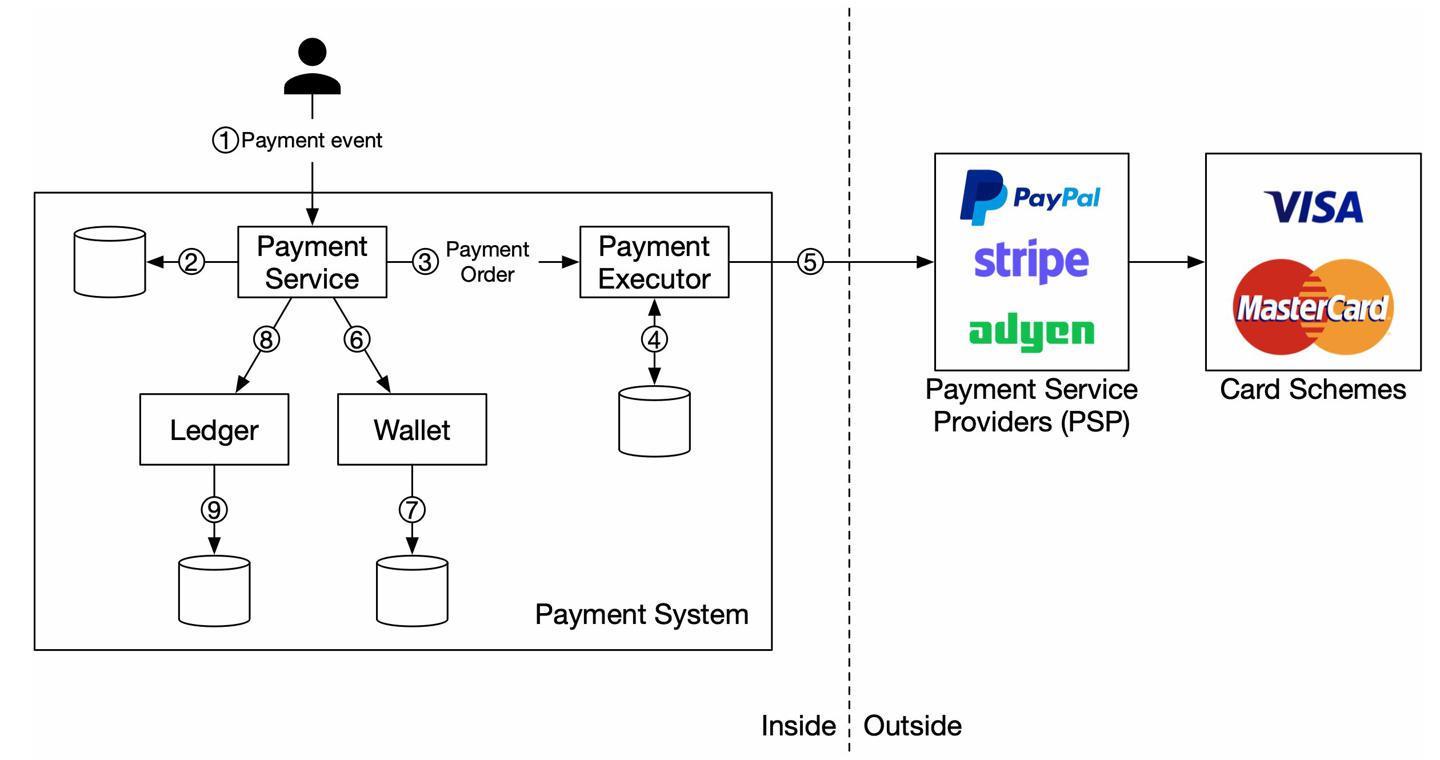
- 用户点击购买按钮,系统生成一个支付事件,下游的支付服务处理这个消息
- 支付服务使用数据库存储「支付事件」「1/6」
- 有时候单个支付事件内包含多个支付订单。
- 比如一次支付中包含了多个商家,此时支付服务调用多个支付接口「2/6」
- 支付服务将支付单存在数据库
- 支付服务调用外部接口
PSP,以完成信用卡支付动作「3/6」 - 支付成功后,支付服务将结果更新到钱包,记录每个商家拿到了多少钱
- 钱包服务将余额更新到数据库「4/6」
- 上一步完成后,支付服务调用总账服务,更新总账
- 总账服务将总账记录到数据库「5/6」
- 每晚
PSP或者信用卡、外部支付平台向客户发送结算文件。- 结算文件中包含了账户余额、当天发生的交易「6/6」
TBD
- 分布式事务一致性,需要细节解析
高并发、高可用、低RT
high concurrency, high availability and quick responsiveness https://twitter.com/alexxubyte/status/1463577613595598854
背景
电商很多活动会带来很多高发流量,系统需要交付高并发、高可用、快速响应的能力。
方案
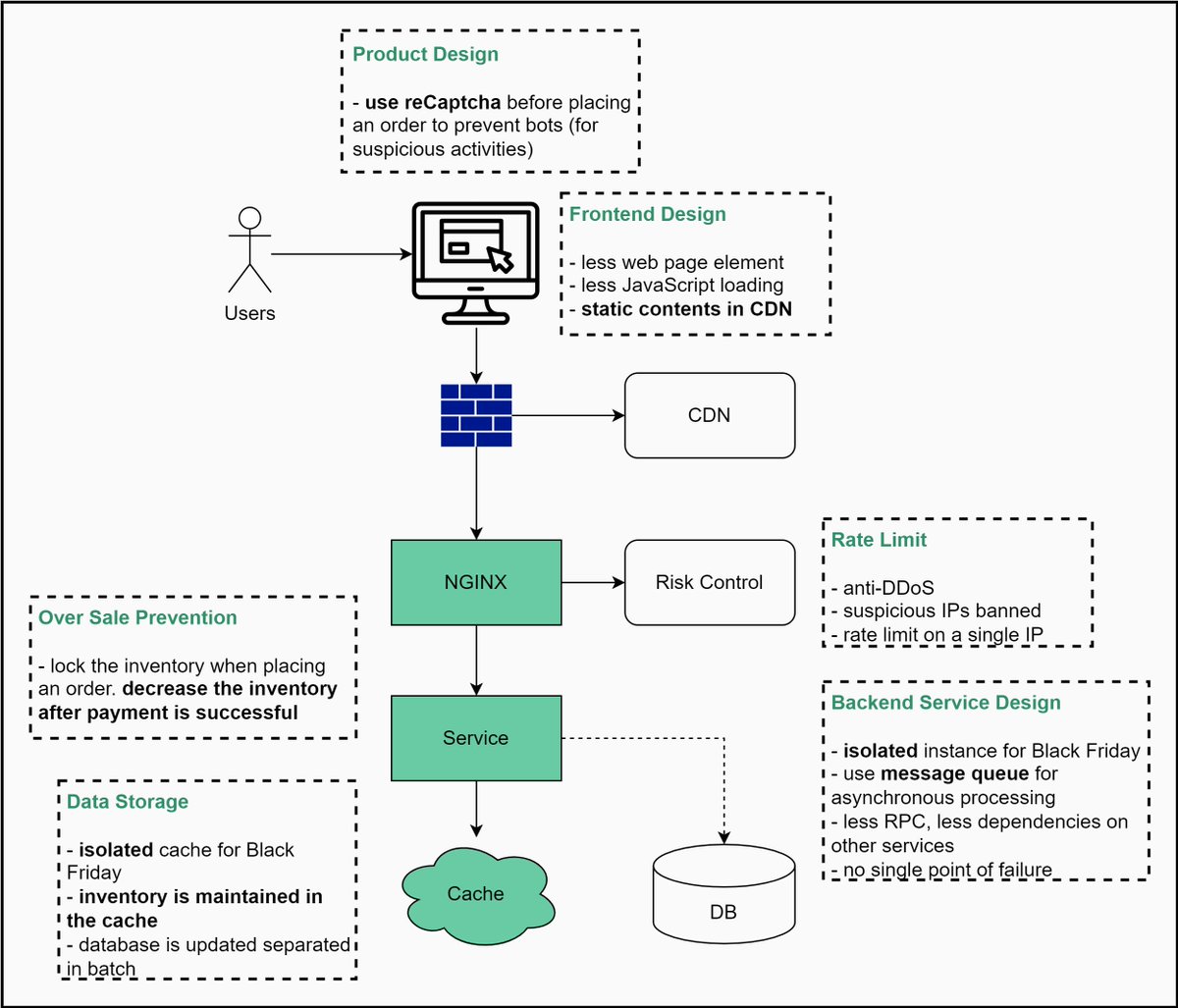
产品设计
- 在用户下单前使用
reCaptcha验证码,防刷
前端设计
- 尽可能少的页面元素
- 尽可能少的
JS加载 - 使用
CDN托管静态文件
网关限流
- 防
DDoS - 限制可疑
IP - 针对单一
IP限流
后端设计
- 针对电商活动使用单独隔离的实例资源
- 使用消息队列
MQ处理异步任务 - 减少依赖的服务,减少
RPC调用 - 减少单点设计(提前容错)
防止超卖
- 下单时锁定库存
- 支付成功后减库存
存储
- 针对电商活动使用单独隔离的缓存资源
- 使用缓存维护库存数据
- 数据库分批更新
设计原则
- 少就是多
- 页面更少元素
- 对存储尽可能少的访问
- 减少接口请求
- 更少的服务依赖
- 最短决策路径
- 减少单一请求内依赖的服务数,或者想办法合并多个服务
- 异步处理
- 使用
MQ处理高TPS
- 使用
- 隔离
- 隔离静态、动态资源
- 隔离进程、服务、存储
- 防止超售
- 考虑好何时扣减库存
- 做好用户体验
- 禁止出现用户已购买成功,但是后续通知却没货
TBD
- 超售设计需要细节